Archive For The “Software” Category
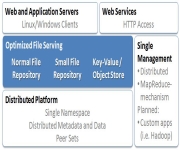
Here’s another innovative application of commodity hardware and innovative software to the high-scale storage problem. MaxiScale focuses on 1) scalable storage, 2) distributed namespace, and 3) commodity hardware. Today’s announcement: http://www.maxiscale.com/news/newsrelease/092109. They sell software designed to run on commodity servers with direct attached storage. They run N-way redundancy with a default of 3-way across storage…
AJAX applications are wonderful because they allow richer web applications with much of the data being brought down asynchronously. The rich and responsive user interfaces of applications like Google Maps and Google Docs are excellent but JavaScript developers need to walk a fine line. The more code they download, the richer the UI they can…
MapReduce has created some excitement in the relational database community. Dave Dewitt and Michael Stonebraker’s MapReduce: A Major Step Backwards is perhaps the best example. In that posting they argued that map reduce is a poor structured storage technology, the execution engine doesn’t include many of the advances found in modern, parallel RDBMS execution engines,…
Erasure coding provides redundancy for greater than single disk failure without 3x or higher redundancy. I still like full mirroring for hot data but the vast majority of the worlds data is cold and much of it never gets referenced after writing it: Measurement and Analysis of Large-Scale Network File System Workloads. For less-than-hot workloads,…
Over the last couple of years, I’ve been getting more interested in Erlang as an high-scale services implementation language originally designed at Ericcson. Back in May of last year I posted: Erlang and High-Scale System Software. The Erlang model of spawning many lightweight threads that communicate via message passing is typically less efficient than the…
Richard Jones of Last.fm has compiled an excellent list of key-value stores in Anti-RDBMS: A list of key-value stores. In this post, Richard looks at Project Voldemort, Ringo, Scalaris, Kai, Dynomite, MemcacheDB, ThruDB, CouchDB, Cassandra, HBase and Hypertable. His conclusion for Last.fm use is that Project Voldemort has the most promise with Scalaris being a…
Last July, Facebook released Cassandra to open source under the Apache license: Facebook Releases Cassandra as Open Source. Facebook uses Cassandra as email search system where, as of last summer, they had 25TB and over 100m mailboxes. This video gets into more detail on the architecture and design: http://www.new.facebook.com/video/video.php?v=540974400803#/video/video.php?v=540974400803. My notes are below if you…
I recently stumbled across: Snippets on Software. It’s a collection of mini-notes on software with links to more if you are interested in more detail. Some snippets are wonderful, some clearly aren’t exclusive to software and some I would argue are just plain wrong. Nonetheless, it’s a great list. It’s too long to read from…
Back in 2000, Joel Spolsky published a set of 12 best practices for a software development team. It’s been around for a long while now and there are only 12 points but it’s very good. Simple, elegant, and worth reading: The Joel Test: 12 Steps to Better Code. Thanks to Patrick Niemeyer for sending this…
Large sorts need to be done daily and doing it well actually is economically relevant. Last July, Owen O’Malley of the Yahoo Grid team announced they had achieved a 209 second TeraSort run: Apache Hadoop Wins Terabyte Sort Benchmark. My summary of the Yahoo result with cluster configuration: Hadoop Wins TeraSort. Google just announced a…
Two weeks ago I posted the notes I took from Tony Hoare’s “The Science of Programming” talk at the Computing in the 21st Century Conference in Beijing. Here’s are the slides from the original talk: Tony Hoare Science of Programming (199 KB). Here are my notes from two weeks back: Tony Hoare on The Science…
Butler Lampson, one of the founding members of Xerox PARC, Turing award winner, and one of the most practical engineering thinkers I know spoke a couple of days ago at the Computing in the 21st Century Conference in Beijing. My rough notes from Butler’s talk follow. Overall Butler argues that “embodiment” is the next big…
Tony Hoare spoke yesterday at the Computing in the 21st Century Conference in Beijing. Tony is a Turing award winner, Quicksort inventor, author of the influential Communication Sequential Processes (CSP) formal language, and long time advocate of program verification and tools to help produce reliable software systems. In his talk he argues that programming should…
An interesting file system study is at this year’s USENIX Annual Technical Conference. The paper Measurement and Analysis of Large-Scale Network File System Workloads looks at CIFS remote file system access patterns from two populations. The first a large file store of 19TB serving 500 software developers and the second a medium sized file store…
Last week the Facebook Data team released Cassandra as open source. Cassandra is an structured store with write ahead logging and indexing. Jeff Hammerbacher, who leads the Facebook Data team described Cassandra as a BigTable data model running on a Dynamo-like infrastructure. Google Code for Cassandra (Apache 2.0 License): http://code.google.com/p/the-cassandra-project/. Avinash Lakshman, Prashant Malik, and…
Jim Gray proposed the original sort benchmark back in his famous Anon et al paper A Measure of Transaction Processing Power originally published in Datamation April 1, 1985. TeraSort is one of the benchmarks that Jim evolved from this original proposal. TeraSort is essentially a sequential I/O benchmark and the best way to get lots…