Archive For October 15, 2008
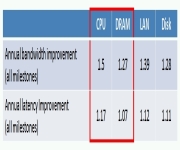
In past posts, I’ve talked a lot about Solid State Drives. I’ve mostly discussed about why they are going to be relevant on the server side and the shortest form of the argument is based on extremely hot online transaction processing systems (OLTP). There are potential applications as reliable boot disks in blade servers and…