Archive For April 7, 2009
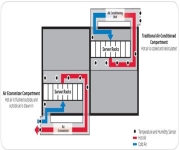
In the talk I gave at the Efficient Data Center Summit, I note that the hottest place on earth over recorded history was Al Aziziyah Libya in 1922 where 136F (58C) was indicated (see Data Center Efficiency Summit (Posting #4)). What’s important about this observation from a data center perspective is that this most extreme…