Archive For November 20, 2010
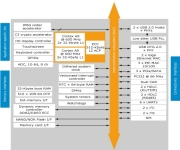
I’m interested in low-cost, low-power servers and have been watching the emerging market for these systems since 2008 when I wrote CEMS: Low-Cost, Low-Power Servers for Internet Scale Services (paper, talk). ZT Systems just announced the R1081e, a new ARM-based server with the following specs: · STMicroelectronics SPEAr 1310 with dual ARM® Cortex™-A9 cores ·…