In the talk I gave at the Efficient Data Center Summit, I note that the hottest place on earth over recorded history was Al Aziziyah Libya in 1922 where 136F (58C) was indicated (see Data Center Efficiency Summit (Posting #4)). What’s important about this observation from a data center perspective is that this most extreme temperature event ever, is still less than the specified maximum temperatures for processors, disks, and memory. What that means is that, with sufficient air flow, outside air without chillers could be used to cool all components in the system. Essentially, it’s a mechanical design problem. Admittedly this example is extreme but it forces us to realize that 100% free air cooling possible. Once we understand that it’s a mechanical design problem, then we can trade off the huge savings of higher temperatures against the increased power consumption (semiconductor leakage and higher fan rates) and potentially increased server mortality rates.
We’ve known for years that air side economization (use of free air cooling) is possible and can limit the percentage of time that chillers need to be used. If we raise the set point in the data center, chiller usage falls quickly. For most places on earth, a 95F (35C) set point combined with free air cooling and evaporative cooling are sufficient to eliminate the use of chillers entirely.
Mitigating the risk of increased server mortality rates, we now have manufacturers beginning to warrant there equipment to run in more adverse conditions. Rackable Systems recently announced that CloudRack C2 will support full warrantee at 104F (40C): 40C (104F) in the Data Center. Ty Schmitt of Dell confirms that all Dell servers are warranted at 95F (35C) inlet temperatures.
I recently came across a wonderful study done by the Intel IT department (thanks to Data Center Knowledge): reducing data center cost with an Air Economizer.
In this study Don Atwood and John Miner of Intel IT take the a datacenter module and divide it up into two rooms of 8 racks each. One room is run as a control with re-circulated air the their standard temperatures. The other room is run on pure outside air with the temperature allowed to range between 65F and 90F. If the outside temp falls below 65, server heat is re-circulated to maintain 65F. If over 90F, then the air conditioning system is used to reduced to 90F. The servers ran silicone design simulations at an average utilization rate of 90% for 10 months.
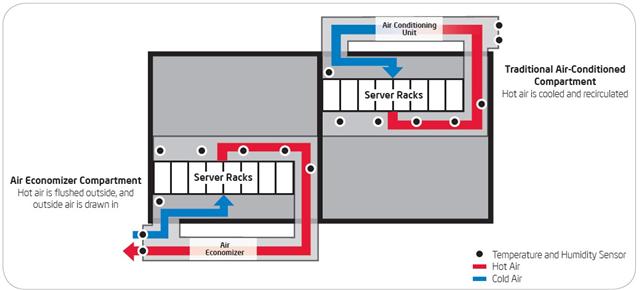.jpg)
The short summary is that the server mortality rates were marginally higher – it’s not clear if the difference is statistical noise or significant – and the savings were phenomenal. It’s only four pages and worth reading: http://www.intel.com/it/pdf/Reducing_Data_Center_Cost_with_an_Air_Economizer.pdf.
We all need to remember that higher temperatures mean less engineering headroom and less margin for error so care needs to be shown when raising temperatures. However, it’s very clear that its worth investing in the control systems and processes necessary for high temperature operation. Big savings await and it’s good for the environment.
–jrh
James Hamilton, Amazon Web Services
1200, 12th Ave. S., Seattle, WA, 98144
W:+1(425)703-9972 | C:+1(206)910-4692 | H:+1(206)201-1859 | james@amazon.com
H:mvdirona.com | W:mvdirona.com/jrh/work | blog:http://perspectives.mvdirona.com
Rick, you commented that “it’s time to do more thinking and less talking” and argued that the additional server failures seen in the Intel report created 100% more ewaste so simply wouldn’t make sense. I’m willing to do some thinking with you on this one.
I see two potential issues with your assumption. The first that the Intel report showed “100% more ewaste”. What they saw in a 8 rack test is server mortality rate of 4.46% whereas their standard data centers were 3.83%. This is far from double and with only 8 racks may not be statistically significant. Further evidence that the difference may not be significant we see that the control experiment where they had 8 racks in the other half of the container running on DX cooling showed failure rates of 2.45%. It may be noise given that the control differed from the standard data center by about as much as test data set. And, it’s a small sample.
Let’s assume for a second that the increase in failure rates actually was significant. Neither the investigators or I are convinced this is the case but let’s make the assumption and see where it takes us. They have 0.63% more than their normal data centers and 2.01% more than the control. Let’s take the 2% number and think it through assuming these are annualized numbers. The most important observation I’ll make is that 85% to 90% of servers are replaced BEFORE they fail which is to say that obsolescence is the leading cause of server replacement. They no longer are power efficient and get replaced after 3 to 5 years. If I could save 10% of the overall data center capital expense and 25%+ of the operating expense at the cost of having an additional 2% in server failures each year. Absolutely yes. Further driving this answer home, Dell, Rackable, and ZT Systems will replace early failures if run under 35C (95F) on warranty.
So, the increased server mortality rate is actually free during the warranty period but let’s ignore that and focus on what’s better for the environment. If 2% of the servers need repair early and I spend the carbon footprint to buy replacement parts but saving 25%+ of my overall data center power consumption, is that a gain for the environment? I’ve not got a great way to estimate true carbon footprint of repair parts but it sure looks like a clear win to me.
On the basis of the small increase in server mortality weighed against the capital and operating expense savings, running hotter looks like a clear win to me. I suspect we’ll see at least a 10F average rise over the next 5 years and I’ll be looking for ways to make that number bigger. I’m arguing it’s a substantial expense reduction and great for the environment.
–jrh
Guys, to be honest I am in the HVAC industry. Now, what the Intel study told us is that yes this way of cooling could cut energy use, but what is also said is that there was more than a 100% increase in server component failure in 8 months (2.45% to 4.46%) over the control study with cooling… Now with that said if anybody has been watching the news lateley or Wall-e, we know that e-waste is overwhlming most third world nations that we ship to and even Arizona. Think?
I see all kinds of competitions for energy efficiency, there should be a challenge to create sustainable data center. You see data centers use over 61 billion kWh annually (EPA and DOE), more than 120 billion gallons of water at the power plant (NREL), more than 60 billion gallons of water onsite (BAC) while producing more than 200,000 tons of e-waste annually (EPA). So for this to be a fair game we can’t just look at the efficiency. It’s SUSTAINABILITY!
It would be easy to just remove the mechanical cooling (I.E. Intel) and run the facility hotter, but the e-waste goes up by more than 100% (Intel Report and Fujitsu hard drive testing), It would be easy to not use water cooled equipment, to reduce water onsite use but the water at the power plant level goes up, as well as the energy use. The total solution has to be a solution of providing the perfect environment, the proper temperatures, while reducing e-waste.
People really need to do more thinking and less talking. There is a solution out there that can do almost everything that needs to be done for the industry. You just have to look! Or maybe call me I’ll show you.
Yeah, NEBS is great. See page 19 of this slide deck for more info: http://mvdirona.com/jrh/TalksAndPapers/JamesHamilton_Google2009.pdf. Its what we want from a temperature perspective although typically not from the pricing side. Thanks Kevin.
–jrh
jrh@mvdirona.com
NEBS-rated equipment gets you really close to this temperature. Telecommunications servers are usually rated to meet NEBS requirements for central offices; they need to handle a 40°C long-term ambient and a 55°C short-term (96-hour) ambient.
JD, my point was that temperatures are kept lower to allow for some time to deal with cooling failures.
I have been quoted a statistic that temperatures will rise by 1C/minute that the cooling is down. If you run at a higher temperature, you run closer to the margin when equipment will shutdown to prevent thermal failure.
So even if you save on operational costs, it may be that a black swan cooling failure event takes down the entire datacenter.
I wasn’t thinking of eliminating the chiller, but that might be an interesting idea as well.
Devdas…
If you are wanting to use that statistic to compare equipment failures at elevated temperatures then that may not be a fair comparison as a data center is typically a closed system and the temperature will continue to rise as long as the IT equipment(Heaters) will stay on, which may be well over the worst case scenario that jrh mentions above. If you are thinking that eliminating the chiller and supporting cooling infrastructure will eliminate points of failure and you would like to see that factored in somewhere then you may have a point. Just my 2cents.
JD
An interesting statistic here would be survival of the equipment in the datacenter when the airconditioning fails.