Archive For May 21, 2008
Search drives the online commerce world by bringing sellers and buyers together. As a seller, you most important task is getting your site to rank high organically and to have your advertisements placed most prominently and most frequently to user interested in buying and only to users interested in your product. A buyer chooses a…
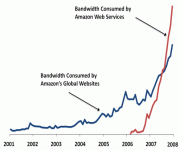
There is no question that cloud computing is going to a big part of the future of server-side systems. What I find interesting is the speed with which this is happening. Look at recent network traffic growth rates from AWS: From: http://aws.typepad.com/aws/2008/05/lots-of-bits.html AWS is now consuming considerably more bandwidth than Amazon’s global web sites. Phenomenal…