Archive For December 19, 2009
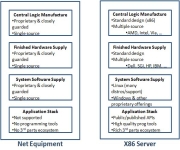
The networking world remains one of the last bastions of the mainframe computing design point. Back in 1987 Garth Gibson, Dave Patterson, and Randy Katz showed we could aggregate low-cost, low-quality commodity disks into storage subsystems far more reliable and much less expensive than the best purpose-built storage subsystems (Redundant Array of Inexpensive Disks). The…