Archive For May 20, 2011
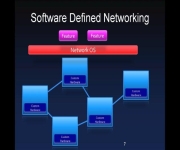
I invited Nikhil Handigol to present at Amazon earlier this week. Nikhil is a Phd candidate at Stanford University working with networking legend Nick McKeown on the Software Defined Networking team. Software defined networking is an concept coined by Nick where the research team is separating the networking control plane from the data plane. The…