Archive For October 25, 2008
Service monitoring at scale is incredibly hard. I’ve long argued that you should never learn anything about a problem your service is experiencing from a customer. How could they possibly know first when there is a service outage or issue? And, yet it happens frequently. The reason it happens is most sites don’t have close…
In When SSDs Make Sense in Server Applications, we looked at where Solid State Drives (SSDs) were practical in servers and services. On the client side, there are even more reasons to use SSDs and I expect that within three years, more than half of enterprise laptops will have NAND Flash as at least part…
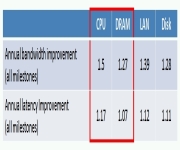
In past posts, I’ve talked a lot about Solid State Drives. I’ve mostly discussed about why they are going to be relevant on the server side and the shortest form of the argument is based on extremely hot online transaction processing systems (OLTP). There are potential applications as reliable boot disks in blade servers and…
Albert Greenberg and I missed Hotnets 2008 last week due to a conflicting meeting down in California but Ken Church was there to present our On Delivering Embarrassingly Distributed Cloud Services paper. I summarized the paper in a recent blog entry: Embarrassingly Distributed Cloud Services and the abstract from the paper follows: Very large data…
Google has long enjoyed a reputation for running efficient data centers. I suspect this reputation is largely deserved but, since it has been completely shrouded in secrecy, that’s largely been a guess built upon respect for the folks working on the infrastructure team rather than anything that’s been published. However, some of the shroud of…