Last Thursday Facebook announced the Open Compute Project where they released pictures and specifications for their Prineville Oregon datacenter and the servers and infrastructure that will populate that facility. In my last blog, Open Compute Mechanical System Design I walked through the mechanical system in some detail. In this posting, we’ll have a closer look at the Facebook Freedom Server design.
Chassis Design:
The first thing you’ll notice when looking at the Facebook chassis design is there are only 30 servers per rack. They are challenging one of the strongest held beliefs in the industry that is density is the primary design goal and more density is good. I 100% agree with Facebook and have long argued that density is a false god. See my rant Why Blade Servers aren’t the Answer to all Questions for more on this one. Density isn’t a bad thing but paying more to get denser designs that cost more to cool is usually a mistake. This is what I’ve referred to in the past as the Blade Server Tax.
When you look closer at the Facebook design, you’ll note that the servers are more than 1 Rack Unit (RU) high but less than 2 RU. They choose a non-standard 1.5RU server pitch. The argument is that 1RU server fans are incredibly inefficient. Going with 60mm fans (fit in 1.5RU) dramatically increases their efficiency but moving further up to 2RU isn’t notably better. So, on that observation, they went with 60mm fans and a 1.5RU server pitch.
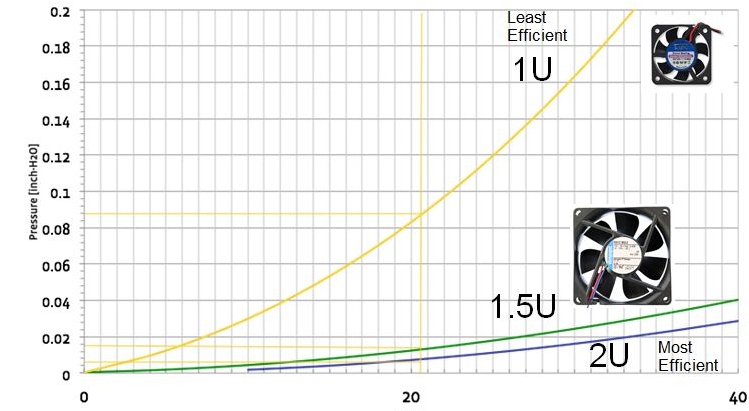
I completely agree that optimizing for density is a mistake and that 1RU fans should be avoided at all costs so, generally, I like this design point. One improvement worth considering is to move the fans out of the server chassis entirely and go with very large fans on the back of the rack. This allows a small gain in fan efficiency by going with larger still fans and allows a denser server configuration without loss of efficiency or additional cost. Density without cost is a fine thing and, in this case, I suspect 40 to 80 servers per rack could be delivered without loss of efficiency or additional cost so would be worth considering.

The next thing you’ll notice when studying the chassis above is that there is no server case. All the components are exposed for easy service and excellent air flow. And, upon more careful inspection, you’ll note that all components are snap in and can be serviced without tools. Highlights:
· 1.5 RU pitch
· 1.2 MM stamped pre-plated steel
· Neat, integrated cable management
· 4 rear mounted 60mm fans
· Tool-less design with snap plungers holding all components
· 100% front cable access
Motherboards:
The Open Compute project supports two motherboard designs where 1 uses an Intel processors and the other uses AMD.
Intel Motherboard:

AMD Motherboard:

Note that these boards are both 12V only designs.
Power Supply:
The power supply (PSU) is an usual design in two dimensions: 1) it is a single output voltage 12v design and 2) it’s actually two independent power supplies in a single box. Single voltage supplies are getting more common but commodity server power supplies still usually deliver 12V, 5V, and 3.3V. Even though processors and memory require somewhere between 1 and 2 volts depending upon the technology, both typically are fed by the 12V power rail through a Voltage Regulator Down (VRD) or Voltage Regulator Module (VRM). The Open Compute approach is to use deliver 12V only to the board and to produce all other required voltages via an Voltage Regulator Module on the mother board. This simplifies the power supply design somewhat and they avoid cabling by having the motherboard connecting directly to the server PSU.

The Open Compute Power Supply is has two power sources. The primary source is 277V alternating current (AC) and the backup power source is 48V direct current (DC). The output voltage from both supplies is the same 12V DC power rail that is delivered to the motherboard.
Essentially this supply is two independent PSUs with a single output rail. The choice of 277VAC is unusual with most high-scale data centers run on 208VAC. But 277 allows one power conversion stage to be avoided and is therefore more power efficient.
Most data centers have mid-voltage transformers(typically in the 13.2kv range but it can vary widely by location). This voltage is stepped down to 480V three phase power in North America and 400V 3 phase in much of the rest of the world. The 480VAC 3p power is then stepped down to 208VAC for delivery to the servers.
The trick that Facebook is employing in their datacenter power distribution system is to avoid one power conversion by not doing the 480VAC to 208VAC conversion. Instead, they exploit the fact that each phase of 480 3p power is 277VAC between the phase and neutral. This avoids a power transformation step which improves overall efficiency. The negatives of this approach are 1) commodity power supplies can’t be used (277VAC is beyond the range of commodity PSUs) and 2) the load on each of the three phases need to be balanced. Generally, this is a good design tradeoff where the increase in efficiency justifies the additional cost and complexity.
An alternative but very similar approach that I like even better is to step down mid-voltage to 400VAC 3p and then play the same phase to neutral trick described above. This technique still has the advantage of avoiding 1 layer of power transformation. What is different is the resultant phase to neutral voltage delivered to the servers is 230VAC which allows commodity power supplies to be used. The disadvantage of this design is that the mid-voltage to 400VAC 3p transformer is not in common use in North America. However this is a common transformer in other parts of the world so they are still fairly easily attainable.
Clearly, any design that avoids a power transformation stage is a substantial improvement over most current distribution systems. The ability to use commodity server power supplies unchanged makes the 400 3p to neutral trick look slightly better than the 480VAC 3p approach but all designs need to be considered in the larger context in which they operate. Since the Facebook power redundancy system requires the server PSU to accept both a primary alternating current input and a backup 48VDC input, special purpose build supplies need to be used. Since a custom PSU is needed for other reasons, going with 277VAC as the primary voltage makes perfect sense.
Overall a very efficient and elegant design that I’ve enjoyed studying. Thanks to Amir Michael of the Facebook hardware design team for the detail and pictures.
–jrh
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
Thanks for the additional detail Susumu.
–jrh
Thank you for informative post regarding "Open Compute Project", James.
In the previous post, Dufresne asked how to handle the transfer from 277VAC to 48VDC, and James replied answering with a diagram would be easier. Now, I found high-level block diagram of the power supply unit in chapter 10 (page 24) of the specification document "450W Power Supply Hardware v1.0". (http://opencompute.org/specs/Open_Compute_Project_Power_Supply_v1.0.pdf)
Looking at the block diagram, you’ll see 277Vac and 48Vdc are converted to different voltages separately by two converters. Several options for ORing the voltages are also shown in the diagram. What is crucial of this tricky design is that the PSU should have two converters in one box. This makes the PSU bigger than usual one. Actually, the cubic volume of this 450W PSU is 1663cc, so the power density is derived as 3.7cc/W (=1663cc/450W), seems rather low compared to recent PSUs being used for servers. We usually do not see this type of PSUs as a cheaper, high volume one.
The specification 5.3 says the bulk voltage is in the range of 430Vdc-440Vdc. Then, one challenge for cheaper PSU that I can come up with is to lift 48Vdc up to 430Vdc and connect backup DC rail directly to the PFC (Power Factor Correction) output in the PSU. By doing so, we could eliminate one converter in the PSU. (Basic idea of this is the same with "Higher Voltage DC" system, widely noticed as an option for high-efficient data centers’ power subsystem design.)
Craig, I suspect you are right that ECC will eventually end up available in parts aimed at markets beyond server and embedded. But, change is slow.
–jrh
James, thanks for confirmation on the graph.
Interesting to see where certain design elements end up in vendors’ market-segmentation strategies. As you noted, at system level some vendors currently offer shared-infrastructure only in higher cost/margin "enterprise" products, and not in lower cost/margin "scale-out" lines. Maybe this increases opportunities for new shared-infrastructure products (e.g. SeaMicro’s).
At processor level, with increasing DNA-sharing between chips marketed for "servers" and those promoted for "client/mobile", I expect to see the server tax continue, but maybe using different distinguishing features. One such feature has been ECC-memory support, even though ECC can also be useful for client. Maybe ECC will go mainstream and vendors will find other features (e.g. on-chip 10GigE ports) that are currently needed more by server applications and less by clients.
Why not eliminate server and rack fans entirely, and rely on the building fans?
Craig, the horizontal access is cubic feet per minute (CFM). Sorry about leaving that off.
Multi-module designs have some upside and can be made quite efficient. However, most of the designs that do this well are blade servers along the lines you mention. Its a good design approach if it can be separated from the rest of the high mark-up design often found in blade serves. See //perspectives.mvdirona.com/2008/09/11/WhyBladeServersArentTheAnswerToAllQuestions.aspx for a longer run down on some of the issues I have with contemporary blade servers designs. The short run down is that turning servers 90 degrees is fine. Using shared infrastructure is a good thing. But most of the current designs are poor price/performers (the server tax problem).
Hi James,
Thanks for this interesting discussion. It looks like the horizontal-axis label on the graph got cut off. Do I understand correctly that this is measuring air volume per unit time?
Regarding power conversion, I’m interested to learn more about cost and efficiency tradefoffs between single-server/single-module designs (e.g. Facebook’s), and multi-server/multi-module designs that turn modules on and off to track total load (e.g. HP’s blade systems). As I understand it, single-module benefits from volume economics, and avoiding multi-module load-sharing circuitry might help full-load efficiency. On the other hand, as you point out multiple shared modules with load-tracking might be more efficient when load is varying, in addition to enabling fault-tolerance via redundancy. Would be interesting to see quantitative analysis of these tradeoffs.
Craig Dunwoody
good ,hope for that!you have mentioned that lower voltage with I^2R loss, we can go even more to lift 48V to 380Vdc, by this you can put the battery to battery room without considering weight problem and tempreture rise for VRLA battery, with thinner power cable, and centerlized 380V big ups system to handle more rack power.
can you show us more details about google battery charge and discharge, with only 5% range of vary? how can they do it?
//Dufresne asked how to handle the transfer from 277VAC to 48VDC. Its a good question and easier to answer with a diagram. I’ll cover the backup power system in the next blog posting.
No, these systems will not be EMI certified. They may be UL certified but, generally, in private datacenters where the servers are not to be resold, some certifications can and are avoided.
–jrh
Have these systems passed certifications (EMI, etc.)? I assume that even if you build them yourselves for your own use that there would be too much liability not to.
If you are happy with the design without change, I suspect Quanta and Synnex would be willing to sell them in smaller numbers.
From: http://opencompute.org/: "We worked with Alfa Tech, AMD, Delta, Intel, Power-One, Quanta and Synnex to develop of the first generation of technologies. We’re working with Dell, HP, Rackspace, Skype, Zynga and others on the next generation."
Will some OEM ever offer something like this? Big players can afford to build out some custom spec system like this because they’re going to need huge data center(s) full of them. I’m assuming middle and little guys would find it too cost-prohibitive to build out a couple copies. At the lower-end, does density (and pretty plastic bezels with der blinkenlights) win out over efficiency?
Dufresne asked how to handle the transfer from 277VAC to 48VDC. Its a good question and easier to answer with a diagram. I’ll cover the backup power system in the next blog posting.
I agree that a central PSU with 12V busbars delivering to the rest of the rack is an option. Delivering 12V over long distances is impractical due to I^2R losses but it is fine for inside the rack distribution. Another limiting factor is a single 10kva to 15kva supply is an expensive, low-volume part. And it also has nasty failure characteristics where a supply failure takes down the entire rack. A more common variant of that design is to have 3 to 6 supplies delivering 12V to a rack level 12vdc bus.
Extending your list of advantages above, I see at least three upsides of this design variant: 1) cheaper, higher volume PSUs can be used, 2) 5+1 can ride through a PSU failure, 3) you can turn supplies off and on as load changes to keep them at their efficiency sweetspot across widely changing server loads. Its a nice approach.
Hi Joe, you were asking about the differences between the Intel and AMD boards. As you point out, its clear they are aimed at different workloads. The AMD board takes 24 DIMMs whereas the intel board is only 6. My guess is the Intel board is used for web servers and the AMD boards are hosting memcached/membase. I’m pretty sure but not positive that the second network port on the AMD board is not used. The primary network port on both boards is an Intel part.
can you explain more about how to transfer from 277Vac to 48Vdc, which is the critical trick for this design.
and how dou you think about to centralize the server power with backbone 12V busbar to every node.by this you can remove psu from server for cost down, and improve load rate for better efficiency,by plug and play.
even more if you add battry on 12V busbar, you can sleep some power module when light load for more efficiency.
Hi James,
Interesting post thanks.
Any comments on my the Intel board is so different to the AMD board?
It seems like the Intel board has only 6 DIMM slots and a single network port, where the AMD has 24 DIMM’s and 2 network ports.
Thanks