AJAX applications are wonderful because they allow richer web applications with much of the data being brought down asynchronously. The rich and responsive user interfaces of applications like Google Maps and Google Docs are excellent but JavaScript developers need to walk a fine line. The more code they download, the richer the UI they can support and the less synchronous server interactions they need. But, the more code they download, the slower the application can be to start. This is particularly noticeable when the client cache is cold and in mobile applications with restricted bandwidth back to the server.
Years ago profile directed code reorganization (a sub-class of Basic Block Transforms) were implemented to solve what might appear to be an unrelated problem. The problem tackled by these profile directed basic block reorganizations is decreasing the number of last level cache misses in a server. They do this by organizing frequently accessed code segments together and moving rarely executed code segments. The biggest gain is that seldom executed error handling code can be moved away from frequently executed application code. I’ve seen reports of error handling code making up more than 40% of an application. Moving this code away from the commonly executed mainline code allows fewer processor cache lines to support program execution which demands fewer memory faults. Error handling code will execute more slowly but that is seldom an issue. Profile directed basic block transforms need to be trained on “typical” applications workloads and code that typically executes together will be placed together. Unfortunately, “typical” is often an important, industry standard benchmark like TPC-C so sometimes “typical” is replaced by “important” :-). Nonetheless, the tools are effective and greater than 20% improvement is common and we often see much more. All commercial database servers use or misuse profile directed basic block reorganizations.
The JavaScript download problem is actually very similar to the problem addressed by basic block transforms. Getting code from the server takes relatively long time just as getting code from memory takes a long time relative to executing code already in the processor cache. Much of the application doesn’t execute in the common case so it makes little sense to download it all unless needed in this execution. Most of the code isn’t needed to start the application so it’s a big win to download the code, start the application, and then download what is needed in the background.
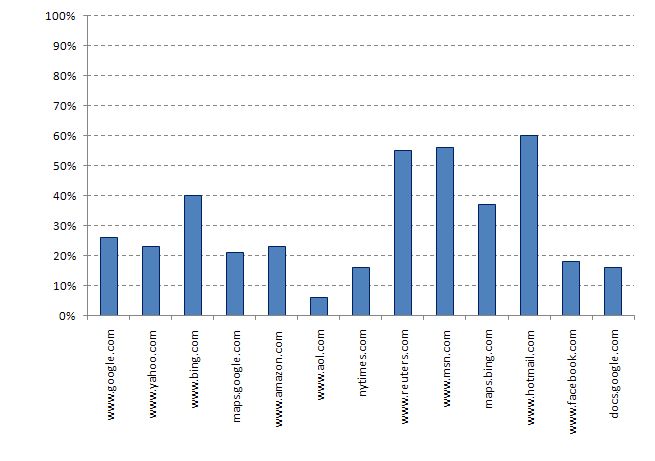
Last week Ben Livshits and Emre Kiciman of the Microsoft Research team released an interesting tool that does exactly this for JavaScript applications. Doloto analyses client JavaScript systems and breaks them up into a series of independent modules. The primary module is downloaded first and includes just stubs for the other modules. This primary module is smaller, downloads faster, and dramatically improves time to live application. In the Doloto team measurements, the size of the initial download was only between 20% and 60% of the size of the standard download. In the case of Google docs, the initial download was less than 20% of the original size.
Once the initial module is downloaded, the application is live and running and the rest of the modules are brought down asynchronously or faulted in as needed. Many applications due these optimizations manually but this is a nice automated approach to the problem
I’ve seen 80,000 line JavaScript programs and there are many out there far larger. Getting the application running fast dramatically improves the user experience and this is a nice approach to achieving that goal. Doloto is available for download at: http://msdn.microsoft.com/en-us/devlabs/ee423534.aspx. And there is a more detailed Doloto paper at: http://research.microsoft.com/en-us/um/people/livshits/papers/pdf/fse08.pdf and summary information at: http://research.microsoft.com/en-us/projects/doloto/.
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com