Archive For October 25, 2011
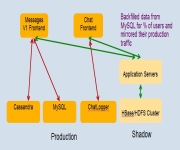
One of the talks that I particularly enjoyed yesterday at HPTS 2011 was Storage Infrastructure Behind Facebook Messages by Kannan Muthukkaruppan. In this talk, Kannan talked about the Facebook store for chats, email, SMS, & messages. This high scale storage system is based upon HBase and Haystack. HBase is a non-relational, distributed database very similar…
Rough notes from a talk on COSMOS, Microsoft’s internal Map reduce systems from HPTS 2011. This is the service Microsoft uses internally to run MapReduce jobs. Interesting, Microsoft plans to use Hadoop in the external Azure service even though COSMOS looks quite good: Microsoft Announces Open Source Based Cloud Service. Rough notes below: Talk: COSMOS:…