One of the talks that I particularly enjoyed yesterday at HPTS 2011 was Storage Infrastructure Behind Facebook Messages by Kannan Muthukkaruppan. In this talk, Kannan talked about the Facebook store for chats, email, SMS, & messages.
This high scale storage system is based upon HBase and Haystack. HBase is a non-relational, distributed database very similar to Google’s Big Table. Haystack is simple file system designed by Facebook for efficient photo storage and delivery. More on Haystack at: Facebook Needle in a Haystack.
In this Facebook Message store, Haystack is used to store attachments and large messages. HBase is used for message metadata, search indexes, and small messages (avoiding the second I/O to Haystack for small messages like most SMS).
Facebook Messages takes 6B+ messages a day. Summarizing HBase traffic:
· 75B+ R+W ops/day with 1.5M ops/sec at peak
· The average write operation inserts 16 records across multiple column families
· 2PB+ of cooked online data in HBase. Over 6PB including replication but not backups
· All data is LZO compressed
· Growing at 250TB/month
The Facebook Messages project timeline:
· 2009/12: Project started
· 2010/11: Initial rollout began
· 2011/07: Rollout completed with 1B+ accounts migrated to new store
· Production changes:
o 2 schema changes
o Upgraded to Hfile 2.0
They implemented a very nice approach to testing where, prior to release, they shadowed the production workload to the test servers.
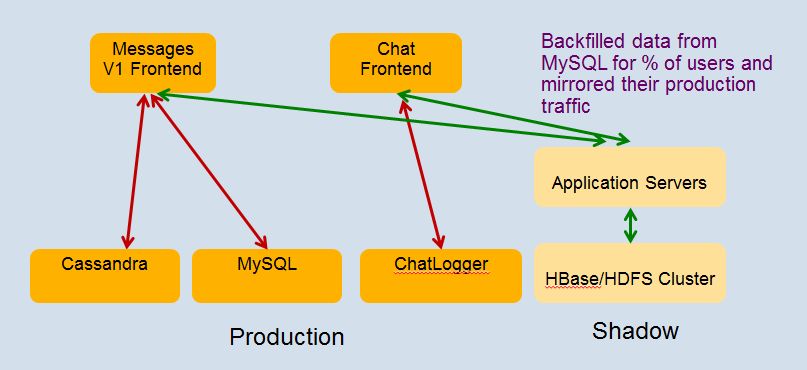
After going into production the continued the practice of shadowing the real production workload into the test cluster to test before going into production:
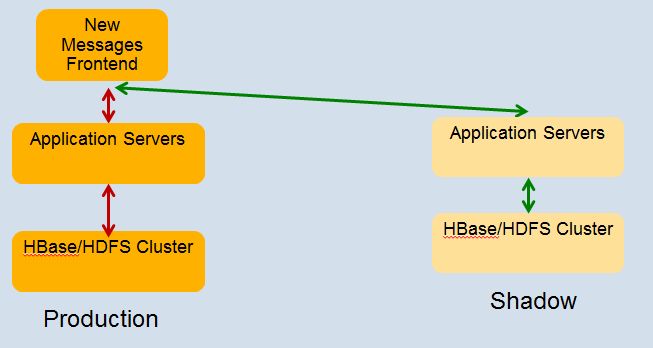
The list of scares and scars from Kannan:
· Not without our share of scares and incidents:
o s/w bugs. (e.g., deadlocks, incompatible LZO used for bulk imported data, etc.)
§ found a edge case bug in log recovery as recently as last week!
· performance spikes every 6 hours (even off-peak)!
o cleanup of HDFS’s Recycle bin was sub-optimal! Needed code and config fix.
· transient rack switch failures
· Zookeeper leader election took than 10 minutes when one member of the quorum died. Fixed in more recent version of ZK.
· HDFS Namenode – SPOF
· flapping servers (repeated failures)
· Sometimes, tried things which hadn’t been tested in dark launch!
o Added a rack of servers to help with performance issue
§ Pegged top of the rack network bandwidth!
§ Had to add the servers at much slower pace. Very manual .
§ Intelligent load balancing needed to make this more automated.
· A high % of issues caught in shadow/stress testing
· Lots of alerting mechanisms in place to detect failures cases
o Automate recovery for a lots of common ones
o Treat alerts on shadow cluster as hi-pri too!
· Sharding service across multiple HBase cells also paid off
Kannan’s slides are posted at: http://mvdirona.com/jrh/TalksAndPapers/KannanMuthukkaruppan_StorageInfraBehindMessages.pdf
–jrh
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com