I am excited by very low power, very low cost servers and the impact they will have on our industry. There are many workloads where CPU is in excess and lower power and lower cost servers are the right answer. These are workloads that don’t fully exploit the capabilities of the underlying server. For these workloads, the server is out of balance with excess CPU capability (both power and cost). There are workloads were less is more. But, with technology shifts, it’s easy to get excited and try to apply the new solution too broadly.
We can see parallels in the Flash memory world. At first there was skepticism that Flash had a role to play in supporting server workloads. More recently, there is huge excitement around flash and I keep coming across applications of the technology that really don’t make economic sense. Not all good ideas apply to all problems. In going after this issue I wrote When SSDs make sense in Server applications and then later When SSDs Don’t Make Sense in Server Applications. Sometimes knowing where not to apply a technology is more important than knowing where to apply it. Looking at the negative technology applications is useful.
Returning to very low-cost, low-power servers, I’ve written a bit about where they make sense and why:
· Very Low-Power Server Progress
· The Case for Low-Cost, Low-Power Servers
· 2010 the Year of the Microslice Computer
· ARM Cortex-A9 SMP Design Announced
But I haven’t looked much at where very low-power, low-cost servers do not make sense. When aren’t they a win when looking at work done per dollar and work done per joule? Last week Dave DeWitt sent me a paper that looks the application of Wimpy (from the excellent FAWN, Fast Array of Wimpy Nodes, project at CMU) servers and their application to database workloads. In Wimpy Node Clusters: What About Non-Wimpy Workloads Willis Lang, Jignesh Patel, and Srinanth Shankar find that Intel Xeon E5410 is slightly better than Intel Atom when running parallel clustered database workloads including TPC-E and TPC-H. The database engine in this experiment is IBM DB2 DB-X (yet another new name for the product originally called DB2 Parallel Edition – see IBM DB2 for information on DB2 but the Wikipedia page is not yet caught up to the latest IBM name change).
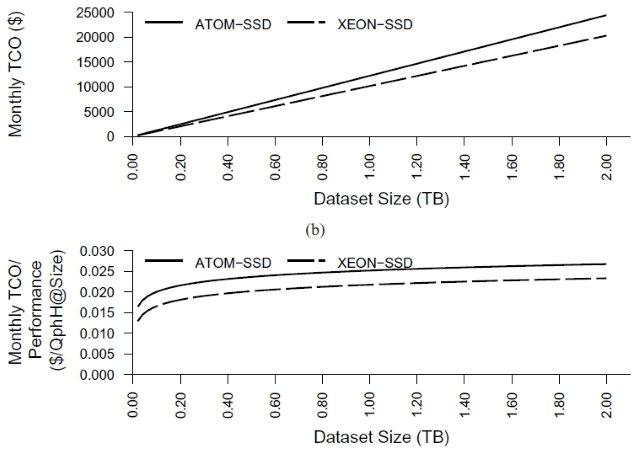
These results show us that on complex, clustered database workloads, server processors can win over low-power parts. For those interested in probing the very low-cost, low-power processor space, the paper is worth a read: Wimpy Node Clusters: What About Non-Wimpy Workloads.
The generalization of their finding that I’ve been using is CPU intensive and workloads with poor scaling characteristic are poor choices to be hosted on very low-power, low-cost servers. CPU intensive workloads are a lose because these workloads are CPU-bound so run best where there is maximum CPU per-server in the cluster. Or worded differently, the multi-server cluster overhead is minimized by having fewer, more-powerful nodes. Workloads with poor scaling characteristics are another category not well supported by wimpy nodes and the explanation is similar. Although these workloads may not be CPU-bound, they don’t run well over clusters with large server counts. Generally, more resources per node is the best answer if the workload can’t be scaled over large server counts.
Where very low-power, low-cost servers win is:
1. Very cold storage workloads. I last posted on these workloads last year Successfully Challenging the Server Tax. The core challenge with cold storage apps is that overall system cost is dominated by disk but the disk needs to be attached to a server. We have to amortize the cost of the server over the attached disk storage. The more disk we attach to a single server, the lower the cost. But, the more disk we attach to a single server, the larger the failure zone. Nobody wants to have to move 64 to 128 TB every time a server fails. The tension is more disk to server ratio drives down costs but explodes the negative impact of server failures. So, if we have a choice of more disks to a given server or, instead, to use a smaller, cheaper server, the conclusion is clear. Smaller wins. This is a wonderful example of where low-power servers are a win.
2. Workloads with good scaling characteristics and non-significant local resource requirements. Web workloads that just accept connections and dispatch can run well on these processors. However, we still need to consider the “and non-significant local resource” clause. If the workload scales perfectly but each interaction needs access to very large memories for example, it may be poor choice for Wimpy nodes. If the workload scales with CPU and local resources are small, Wimpy nodes are a win.
The first example above is a clear win. The second is more complex. Some examples will be a win but others will not. The better the workload scales and the less fixed resources (disk or memory) required, the bigger the win.
Good job by Willis Lang, Jignesh Patel, and Srinanth Shankar in showing us where wimpy nodes lose with detailed analysis.
James Hamilton
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
Maht asked: At first there was skepticism that Flash had a role to play in supporting server workloads. More recently, there is huge excitement around flash …
When you say "at first" what timescale do you mean?
I first got interested in flash memory and its application to data intensive server workloads in early 2006 when Jim Gray sent me a short note on why flash was the right answer for random I/O bound workloads. That note eventually grew to a longer Microsoft internal article that was published a couple of years later as Flash Disk Opportunity for Server Workloads (http://queue.acm.org/detail.cfm?id=1413261).
Clearly these ideas have been around since before 2006 as you point out but that’s when I became convinced that this is a technology change that is going to be super important especially to OLTP database workloads.
–jrh
jrh@mvdirona.com
I like your direction Greg. For memory-intensive caching workloads like memcached, build very large memories either with low-power memory parts or with a combination of memory and NAND. I like it. In this case the advantages of using low-cost parts might exceed the savings of using low-power memory. But using cheap, slow, low-power memory could clearly be a huge win for memcached.
This goes back to my previous comment. For very high-scale workloads — workloads where there are 1,000s to 10s of thousands of servers, it is worth optimizing the server for that workload. Memcached server fleets are getting huge and its not at all uncommon to see 1,000s in a fleet at a big service. This workload is worth optimizing the support. I like your suggestion of using very large memories of based upon low-cost, low-power parts or a two-tier design based upon Flash in the slow tier and memory in the fast tier. I’ll almost guarantee that there are multiple start-ups working on the later as we speak.
I’ll dig deeper into the low-power, low-cost memory suggestion. I think it has considerable merit. Thanks Greg.
–jrh
jrh@mvdirona.com
I hear you Alan and, you are right, less server diversity get us closer to "any machine can run any workload" goal. Its a great place to be. But, if you are running a large fleet of 1,000 of servers serving, the savings of choosing a platform tailored for that service can give big gains. And big gains multiplied by 1,000 of servers is impossible to ignore. Workloads running at very high scale are worth optimizing and, even though, homogeneous servers have real advantages, these mega-workloads are worth optimizing for.
For customer workloads running on on services like EC2, the temptation is again there to provide a single server type for the reasons you specified. But, each customer would prefer servers optimized for them. Clearly, its impossible to produce optimized servers for every possible customer workload. But, with a very large customer base, many different server offerings are possible. This allows each customer to get a server that is very close to optimized for their use and yet the overall fleet is not over partitioned because there are huge numbers of customers choosing each server type.
The workloads that shouldn’t be optimized for are the low-scale workloads that run on single servers to 10s of servers. Running these on customized, non-interchangeable fleets is more likely to be a mistake.
Generally, I agree with you Alan that per-workload optimization doesn’t make sense but mega-scale workloads are worth optimizing for as are very large equivalence classes of general purpose workloads. At scale, it is worth optimizing the servers hardware.
–jrh
jrh@mvdirona.com
> At first there was skepticism that Flash had a role to play in supporting server workloads. More recently, there is huge excitement around flash …
When you say "at first" what timescale do you mean?
Flash was being successfully used in 1990s HPC / MMP machines as part of the cache subsystem.
It also strikes me that many of the hardware based solutions from then are being moved into the modern software stack and I suspect that is the result of trying to push the square Linux / Windows pegs into the round performance hole; trying to implement dataflow hardware concepts into non-dataflow CPUs.
I’d say it would end in tears but plenty of us cry inside already.
Great point, James, on fine-grained partitioning of the cache for wimpy servers. It can be difficult in applications to efficiently work with very fine-grained cache partitioning though.
There is still the question of whether it is more cost efficient for our many common memory intensive workloads to run not on large servers, not on wimpy servers, but servers specifically designed to maximize memory while minimizing power consumption.
Let me risk being more specific here and throw out a crazy idea. Do you know of anyone computing total cost of ownership of normal large server configurations, wimpy servers backed with flash memory (as in the papers you cited), and servers loaded with low power memory (like the newer lower power DDR3 or even the new large capacity LPDDR2) for these common high memory workloads so many see on their servers? Or this idea of trying low power memory too silly (compared to either using normal memory or backing with flash memory)?
In general, what I am wondering here is whether we are going to see a move in the industry away from emphasizing more cores and more speed, towards minimizing power consumption, not only on laptops and mobile devices, but also on servers. The current low memory components may not be well designed for server use, but perhaps we should question if they should be.
How general is a workload, how accurately can we control what type of application and therefore workload sits on which server? James, you know this better than anyone: can we ever get to the point where we can generalize about what type of server architecture can be bound to which processes? Are the expensive server CPUs overkill for servicing inbound connections and handoff to a URL dispatcher? Will the next process be video compression. Hmmm.
I thought that data center builders wanted to make the racks as homogenous as possible, as general as hell, and we got what we wanted, power hungry, general purpose CISC (primarily) hot to the touch servers.
Special purpose appliances for the data center – I generally do not like -XML boxes, application routers, memcached boxes (ye gads!), but here, James, have you stumbled upon an exception?
Can we make a better, low cost low power Http connection aggregator server that can do "other stuff", but is never used for…you know, SAP, etc. That’s the function of Web Servers generally, to hand off a connection to an application and data storage system.
hmmm…
Thanks for adding your thoughts Dave. I hear you on retuning being needed. The workloads I’ve gone after with Wimpy nodes have been "embarrassingly wimpy" not because other workloads can’t win but because I need to have service that is willing to test with me. If I require code changes, they ask me to go away :-).
If you can re-architect the app, that opens the aperture considerably. I argue that, even with big changes, many workloads aren’t great candidates to go wimpy.
I 100% agree that more cores makes a HUGE difference. In discussions with ARM folks, I’ve been arguing they need 4 cores to really handle a good set of interesting server workloads and more than 4 cores would clearly expand the set of workloads that win.
4GB of memory is a problem for some workloads and neither Atom nor ARM can do more at this point in time. Atom is still without ECC which makes it a poor choice for server workloads but Intel knows this and could technically fix the problem in months if the will was there.
Another challenge is the wimpy competition is getting better. A low bin Nehalem does well especially for those buyers that get big volume discounts. However, even with the competition improving, wimpy wins on many workloads. The reason why cell phones, printers, lan devices, … all use low-power, low-cost processors is its a clear win for these workloads. Not all but many.
–jrh
jrh@mvdirona.com
Thanks for the editing Greg. Here’s I was all excited by blogging from a damn airplane and I went and got sloppy :-)
I like your suggestion of going after workloads with high memory to CPU ratios. The Challenge with these workloads that require lots of memory is they scale out badly. Each server needs a very large memory. If you go with more smaller servers, each still needs the big memory. For these workloads, those that I call "significant local resoruce requirements" big servers can be the better answer.
If you can partition the cache, wimpy nodes can be a win. But, if you need a big memory for any number of connections, then larger servers tend to win. Basically if the cost of entry is a big memory, then add as many concurrent connections as you can until you run out of memory bus bandwidth. In many cases, this will be a non-wimpy workload.
Summary: there are two issues: 1) wimps can’t address big memories and 2) if you need a big fixed resource like memory, then you want to heap on as many consumers of that resource as will fit.
But, if you can partition the cache, the wimps can win.
Thanks for the pointer, James!
Two points I’d love for people to note, in general, when thinking about wimpy nodes:
1) Almost every time we’ve run applications on them, we’ve had to re-tune or re-architect them to run well on wimpies. Most high-performance applications are tuned for the capabilities, cache size, and memory size of larger server processors. You should expect that when you take a "regular" application that it will probably run poorly on a wimpy until you’ve applied the same level of optimization for the wimpy platform that has already been applied for the traditional platform.
2) As Greg noted above, the total amount of memory per node can be one of the biggest determiners of how big a processor you really want to use. Some of this is ‘just’ engineering (atoms can’t address very much memory) and some of it is, again, achieving balance: 64GB of memory per node can provide an awful lot of memory bandwidth, so you may need many many cores on the node to take advantage of it.
I’d argue that in the latter case, you might want something more like a "wimpy server" processor — e.g., the new quad-core 1.866Ghz xeon — but I would be willing to wager that the "many cores, low GHz" approach can still win out even if you have to have lots of cores.
Hey, James, thanks for posting this. I’ve been thinking about this issue a lot too.
Quickly, a couple typos. The title ("Low-Cosr" -> "Low-Cost") and you have a broken link for the paper, "Wimpy Node Clusters: What About Non-Wimpy Workloads".
More importantly, could you elaborate on the second case at the end of your article? What I have been wondering about is whether what a lot of applications need is low-CPU, high-memory, low power servers.
This is not quite the tradeoff you are discussing. These boxes would be configured with low power CPUs but a lot of memory.
What do you think about that? Not only do many web apps depend on memory-heavy caching layers (e.g. memcached) these days, but also any database doing random access benefits from having large in-memory caches. Seems to me that the sweet spot for these applications would be keeping as much in memory at the lowest cost (up-front and power costs) possible.
But it is a bit of a different tradeoff than wimpy boxes with Atom processors. We aren’t seeking wimpy. We want the most memory we can pack into the box at the lowest cost over the lifetime of the box. If the boxes end up wimpy, that is just a side effect of our attempt to maximize memory.
Thoughts?