Last week, Sudipta Sengupta of Microsoft Research dropped by the Amazon Lake Union campus to give a talk on the flash memory work that he and the team at Microsoft Research have been doing over the past year. Its super interesting work. You may recall Sudipta as one of the co-authors on the VL2 Paper (VL2: A Scalable and Flexible Data Center Network) I mentioned last October.
Sudipta’s slides for the flash memory talk are posted at Speeding Up Cloud/Server Applications With Flash Memory and my rough notes follow:
· Technology has been used in client devices for more than a decade
· Server side usage more recent and the difference between hard disk drive and flash characterizes brings some challenges that need to be managed in the on-device Flash Translation Layer (FTL) or in the operating systems or Application layers.
· Server requirements are more aggressive across several dimensions including required random I/O rates and higher reliability and durability (data life) requirements.
· Key flash characteristics:
· 10x more expensive than HDD
· 10x cheaper than RAM
· Multi Level Cell (MLC): ~$1/GB
· Single Level Cell (SLC): ~$3/GB
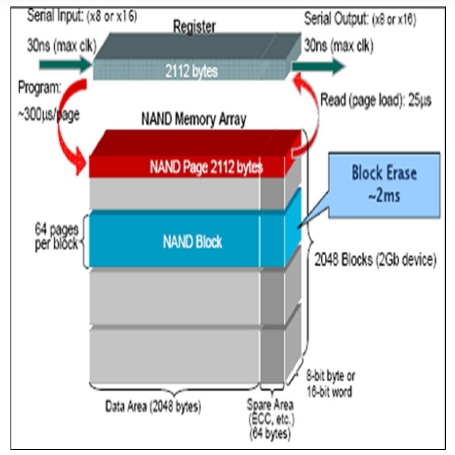
· Laid out as an linear array of flash blocks where a block is often 128k and a page is 2k
· Unfortunately the unit of erasure is a full block but the unit of read or write is 2k and this makes the write in place technique used in disk drives not workable.
· Block erase is a fairly slow operation at 1500 usec whereas read or write is 10 to 100 usec.
· Wear is an issue with SLC supporting O(100k) erases and MLC O(10k)
· The FTL is responsible for managing the mapping between logical pages and physical pages such that logical pages can be overwritten and hot page wear is spread relatively evenly over the device.
· Roughly 1/3 the power consumption of a commodity disk and 1/6 the power of an enterprise disk
· 100x the ruggedness over disk drives when active
· Research Project: FlashStore
· Use flash memory as a cache between RAM and HDD
· Essentially a flash aware store where they implement a log structured block store (this is essentially what the FTLs do in the device implemented at the application layer.
· Changed pages are written through to flash sequentially and an in-memory index of pages is maintained so that pages can be found quickly on the flash device.
· On failure the index structure can be recovered by reading the flash device
· Recently unused pages are destaged asynchronously to disk
· A key contribution of this work is a very compact form for the index into the flash cache
· Performance results excellent and you can find them in the slides and the papers referenced below
· Research Project: ChunkStash
· A very high performance, high throughput key-value store
· Tested on two production workloads:
· Xbox Live Primetime online gaming
· The storage dedeuplication test is a good one in that dedupe is most effective with a large universe of objects to run deduplication over. But a large universe requires a large index. The most interesting challenge of deduplication is to keep the index size small through aggressive compaction
· The slides include a summary of dedupe works and shows the performance and compression ratios they have achieved with ChunkStash
For those interested in digging deeper, the VLDB and USENIX papers are the right next stops:
· http://research.microsoft.com/apps/pubs/default.aspx?id=141508 (FlashStore paper, VLDB 2010)
· http://research.microsoft.com/apps/pubs/default.aspx?id=131571 (ChunkStash paper, USENIX ATC 2010)
· Slides: http://mvdirona.com/jrh/talksandpapers/flash-amazon-sudipta-sengupta.pdf
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
Super interesting question Greg and right now we’re seeing examples of just about every possibility at every level. We have hybrid disks, flash and disk in NAS devices, flash and disk mixes in SAN devices, special purpose storage appliance with a flash/disk mix, o/s support for flash and disk, and hybrid solutions at the App level. Your bet that integrating below well defined interfaces like SAS or SATA and not requiring app changes will have a large part of the market makes sense to me.
James Hamilton
The FlashStore work makes me wonder again if the sweet spot for flash memory in server applications is going to be tightly integrating them into hard drives. Almost always people are using flash as a secondary cache between RAM and hard disk (much less frequently as an attempt to reduce costly RAM, more often people want to speed slow disk). And, I wonder how much value they are getting out of having a specialized, custom flash cache built using separate SSDs (like FlashStore) versus a more general flash cache tightly integrated to the hard disk in a hybrid drive. Perhaps the end game here is widespread use of hybrid drives in servers. Guess we’ll see in a few years.
Simon, I may be thinking impractical thoughts but why the heck would you buy an Niagra box from a vendor that won’t let you install an Intel X25-M SSD. That’s just nuts.
As much as I love the Niagra Architecture and it truly is a thing of beauty, I personally lean towards commodity servers. But, ignore that. The key point is if you buy a server and you are "not allowed" to install a broadly used SSD, you’re buying from the wrong vendor.
–jrh
I agree with @Fazal that Sun’s work is worth looking at. In particular L2ARC ("cachezilla") seems a nice and elegant way to use SSD as an additional read cache layer between RAM and disk. In http://blogs.sun.com/brendan/entry/test , Brendan Gregg describes how this is implemented: a periodic job goes through the "tail" of the RAM cache to salvage those blocks to SSD that are in imminent danger of being dropped when there’s memory pressure. I had planned to use this on a mirror archive server we run, but our vendor wouldn’t support cheap MLC flash (such as the Intel X25-M) in our Niagara box *sigh*.
After the addition of the Cluster Compute and Cluster GPU instances (although I wish they were using Westmere CPUs), SSDs are the major thing missing indeed. Great to hear that it’s being worked on and looking forward to the beta!
Best,
Ismael
Thanks for pointing out the transcription error on my behalf Fazal. I’ll make the correction in the text.
You are not the first to mention you could use very high IOPS rates delivered consistently from EBS. We’re working on it and have lots improvements in mind. I’m looking forward to getting some of these in beta so you can test them with your DB workloads.
–jrh
I think you have the SLC/MLC pricing mixed up. SLC is significantly more expensive than MLC. What’s more, MLC prices are falling due to economies of scale from mobile phones, media players and laptop SSDs, whereas SLC prices and capacities have remained mostly static.
Sun’s work on ZFS and hybrid storage pools should be mentioned as well. You can use SSDs to speed up writes (logzilla) and as a level 2 cache for data (L2ARC/cachezilla), and Sun/Oracle actually uses different devices with characteristics optimized for the two roles in their 7000 series storage appliances.
I wish Amazon would provide SSD-powered low-latency high-I/O instances similar to the high-memory or GPU-accelerated instances already available. My company has write-intensive database workloads that we are currently running on EC2, but planning to migrate to physicalized hosted servers for performance/throughput reasons.
Yes, super important point Frank. When compressing redundancy out of data, the value of what is left is far higher. Loosing a single block could destroy thousands of unrelated objects.
The best defense is to selectively add back redundancy. Essentially, dedupe all blocks but store the remaining representatives with lots of redundancy.
Dedupe is often used on cold data so one approach I like a lot is to dedupe to get a small number of blocks, compress each block to reduce the size, and then pack onto reasonable sized (order 1M) sequential runs and then aggressively erasure encode these blocks.
–jrh
The deduplication pages in the slides referred to the savings associated with having the hardware optimize the storage of "weekly full backups over 8 weeks, 6 week retention", compressing it apparently 20-fold.
My question is to what extent the storage system is justified in performing this optimization. If a naive user wanted "8 full backups", that user probably expects some increased robustness of the data. With deduplication, the naive user’s imagined redundancy is summarily eliminated, so that a localized storage failure turns out to impact many purportedly independent "full backups". Is this a reasonable concern?