This is a guest blog post on Perspectives from Colm MacCarthaigh, a senior engineer on the Amazon Web Services team that designed and built the new VPC Network Address Translation Gateway service that just went live yesterday.
Over the last 25 years, Network Address Translation (NAT) has become almost ubiquitous in networks of any size. The mobile phone in your pocket, or the very cheapest Wi-Fi router you can buy, almost certainly supports sharing its external IP address with other dependent devices using NAT. At the other end of the market, dedicated appliances costing hundreds of thousands of dollars to perform NAT on tens of gbit/sec of traffic are not uncommon.
Besides allowing many devices share a single IP address, NAT is widely used as a security tool. When a device is “behind” NAT it can access the internet and reach the services it needs – such as software updates – but the device itself isn’t directly reachable from the outside world. It’s a simple one-way door that means each device doesn’t have to be hardened to tolerate internet-scale traffic volumes, and it reduces the exposure of any locally running services.
The security aspects of NAT make it popular with our customers, and at AWS we’ve supported VPC NAT instances for many years. These instances are managed and scaled the same way that home routers and enterprise appliances are; if you need to push more traffic or handle more connections, you need a bigger box – the scaling is vertical, and if your instance suffers from some kind of failure, you need to use fail-over or replacement to recover, and there’ll be an interruption to service when that happens. That’s not how modern services are built; it’s better to scale horizontally, and systems should have fault-tolerance built-in, so the reasons that NAT has remained a stalwart example of legacy architectures are interesting.
Fundamentally, NAT works by rewriting the details of a connection on the fly: an instance connects to an IP address and port, say 192.0.2.50 on port 443, and it uses its own source IP and an ephemeral source port it assigns locally, say: 10.0.0.5 and 3683.
On the way out, NAT intercepts the connection and rewrites the source IP and source port parts. The source IP will become whatever the shared IP address is and that’s straight-forward, but rewriting the port is harder because every connection that happens to have the same destination IP and port must be given a uniquely assigned source port. That might seem like an edge case: how common is it to see many connections to the same address and port in the first place? Thousands of hosts behind a NAT checking for security updates at the same time, many worker hosts connecting to dynamodb for queries, or simple clock synchronization using NTP are all day-to-day examples that trigger this.
There are some naïve sharding strategies that could help here; for example, the port range could be split across several machines, each responsible for uniqueness within their shard, but this leads to an inefficient allocation of ports. There’s also the difficult problem of adding shards without interruption, and there are security reasons for the ports to be unpredictably random, which makes associating a port with a shard very difficult when a reply packet comes back.
The result is that when the connection is being set up, a NAT implementation has to efficiently find all of the connections there might be to the same destination / port pair, and make sure that it picks and assigns a unique port in an atomic and transactional way. This is essentially an indexing problem – familiar from the world of databases and commonly expected to take milliseconds – inserted into the set up of every new connection: a world which operates in tens to hundreds of microseconds. So it’s not surprising that the answer has generally been to do it in memory on a single box; and to keep making the box bigger and faster.
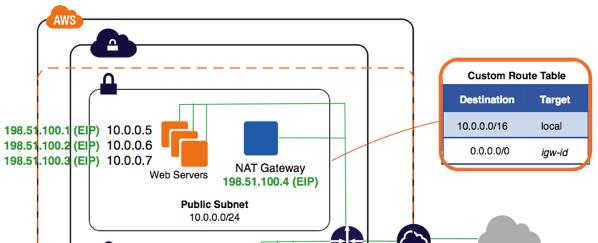
Yesterday we announced the availability of VPC NAT gateways. It’s easy to create and use a NAT Gateway and you can think of it as a new “even bigger” box, but under the hood NAT gateways are different. The connections are managed by a fault-tolerant co-operation of devices in the VPC network fabric. Each new connection is assigned a port in a robust and transactional way, while also being replicated across an extensible set of multiple devices. In other words: the NAT gateway is internally horizontally scalable and resilient.
This is all possible due to the latencies we see with EC2 Enhanced networking. Within an availability zone, round-trip times are now tens of microseconds, which make it feasible to propose and commit transactions to multiple resilient nodes in less than a millisecond.
Building it in to the VPC network fabric also means that VPC NAT Gateways are first class objects of Amazon VPC; a VPC NAT Gateway can be associated with a specific elastic IP address, you can enable flow logs on a VPC NAT Gateway to collect connection-level data, and you can control what a NAT gateway can reach using Network ACLs. Security groups, the stateful version of network ACLs, aren’t supported directly on the NAT Gateway but a NAT Gateway already tracks the state of every connection, so the effect of using Network ACLs is identical.
The biggest benefit though is that VPC NAT Gateways replace an appliance or instance that you otherwise have to run and manage yourself. Considering the near-ubiquity of NAT, it’s exciting to make it available directly from the VPC network fabric.
Thanks. Nice article.
Would love a few details on the implementation. Distributed atomic transactions for Linux conntrack? With RAFT?
Good stuff. What’s the ARN representing the Nat Gateway, and can we use that as a Principal for policies? I don’t yet see documentation inclusive of this.
Thanks for the post, Colm. Last time I mis-spell MASQEURADE.
…IPTABLES