The networking world remains one of the last bastions of the mainframe computing design point. Back in 1987 Garth Gibson, Dave Patterson, and Randy Katz showed we could aggregate low-cost, low-quality commodity disks into storage subsystems far more reliable and much less expensive than the best purpose-built storage subsystems (Redundant Array of Inexpensive Disks). The lesson played out yet again where we learned that large aggregations of low-cost, low-quality commodity servers are far more reliable and less expensive than the best purpose-built scale up servers. However, this logic has not yet played out in the networking world.
The networking equipment world looks just like mainframe computing ecosystem did 40 years ago. A small number of players produce vertically integrated solutions where the ASICs (the central processing unit responsible for high speed data packet switching), the hardware design, the hardware manufacture, and the entire software stack are stack are single sourced and vertically integrated. Just as you couldn’t run IBM MVS on a Burrows computer, you can’t run Cisco IOS on Juniper equipment.
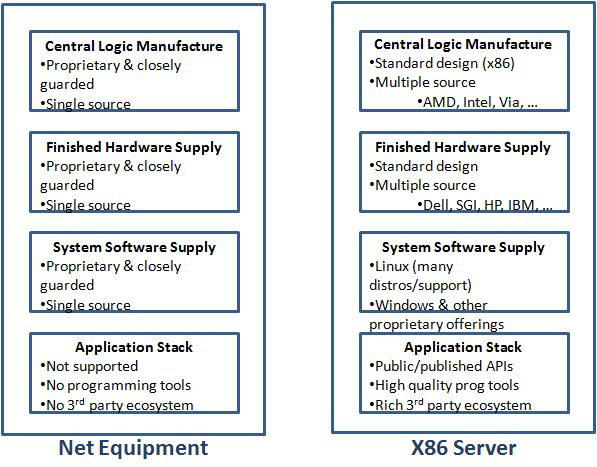
When networking gear is purchased, it’s packaged as a single sourced, vertically integrated stack. In contrast, in the commodity server world, starting at the most basic component, CPUs are multi-sourced. We can get CPUs from AMD and Intel. Compatible servers built from either Intel or AMD CPUs are available from HP, Dell, IBM, SGI, ZT Systems, Silicon Mechanics, and many others. Any of these servers can support both proprietary and open source operating systems. The commodity server world is open and multi-sourced at every layer in the stack.
Open, multi-layer hardware and software stacks encourage innovation and rapidly drive down costs. The server world is clear evidence of what is possible when such an ecosystem emerges. In the networking world, we have a long way to go but small steps are being made. Broadcom, Fulcrum, Marvell, Dune (recently purchased by Broadcom), Fujitsu and others all produce ASICs (the data plane CPU of the networking world). These ASICS are available for any hardware designer to pick up and use. Unfortunately, there is no standardization and hardware designs based upon one part can’t easily be adapted to use another.
In the X86 world, the combination of the X86 ISA, hardware platform, and the BIOS forms a De facto standard interface. Any server supporting this low level interface can host the wide variety of different Linux systems, Windows, and many embedded O/Ss. The existence of this layer allows software innovation above and encourages nearly unconstrained hardware innovation below. New hardware designs work with existing software. New software extensions and enhancements work with all the existing hardware platforms. Hardware producers get a wider variety of good quality operating systems. Operating systems authors get a broad install base of existing hardware to target. Both get bigger effective markets. High volumes encourage greater investment and drive down costs.
This standardized layer hasn’t existed in the networking ecosystem as it has in the commodity server world. As a consequence, we don’t have high quality networking stacks able to run across a wide variety of networking devices. A potential solution is near: OpenFlow. This work originating out of the Stanford networking team driven by Nick McKeown. It is a low level hardware independent interface for updating network routing tables in a hardware independent-way. It is sufficiently rich to support current routing protocols and it also can support research protocols optimized at high-scale data center networking systems such as VL2 and PortLand. Current OpenFlow implementations exist on X86 hardware running linux, Broadcom, NEC, NetFPGA, Toroki, and many others.
The ingredients of an open stack are coming together. We have merchant silicon ASIC from Broadcom, Fulcrum, Dune and others. We have commodity, high-radix routers available from Broadcom (shipped by many competing OEMs), Arista, and others. We have the beginnings of industry momentum behind OpenFlow which has a very good chance of being that low level networking interface we need. A broadly available, low-level interface may allow a high-quality, open source networking stack to emerge. I see the beginnings of the right thing happening.
· OpenFlow web site: http://www.openflowswitch.org/
· OpenFlow paper: Enabling Innovation in Campus Networks
· My Stanford Clean Slate Talk Slides: DC Networks are in my way
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
I work on mainframe systems and the network cards can recover from a failure inflight with no lost connections. It’s what enterprise hardware does. But it is very expensive hardware! Big financial companies are willing to pay for the RAS. This was a very good piece and I enjoyed reading it.
Having worked at IBM for a decade I know the Z-series reasonably well. Generally nice equipment but, as you said, not the best price performer. These systems are sold at a premium on the basis of superior reliability, availability, and servicability. But, it’s impportant to keep in mind that the highest scale and most stable transaction systems in the world are now run on clusters of distribute systems. IBM RAS is very good but it’ll never be as good as a multi-datacenter distributed cluster. The latter is deffinitely a bit harder to engineer but these days, if I had to go looking for great distributed systems engineers or really good Z-series engineers, I would rather search for the former.
That’s about to change Tony. Commodity routing is on its way.
–jrh
jrh@mvdirona.com
Yes – I would say switching is a commodity (1.5-2.5K a pop). Routing however is closed. 65xx Cisco box goes for about $80K. Our network group always insists on redundancy. So for most of our implementations for smaller sites (for a bank) the cost of network equipment far exceeds our X86 hardware costs.
Also the requirement for switches is on the decline due to Blade technologies like Virtual Connect that can be integrated into HP’s C7000 style chassis.
Exactly Guido! Thanks for the data point.
jrh@mvdirona.com
To add some numbers to the cost discussion, a 48x1Gb+4x10Gb switch is available from a number of OEMs around $2-3k. This means you pay around $2500/88Gb = $28/Gb. For the Dell it ends up as $1500/10Gb = $150/Gb. If you buy the switches in quantity, you will end up even lower. And if you move to high-density 10Gb switches, the difference increases. For the time being it’s hard to see general purpose CPUs become competitive with ASICs.
I can’t get a Dell R210 (or other X86 net gear solution) to cost effectively routing 48 (or even 24) ports. When doing highly repetitive operations like packet routing, its hard to beat special purpose hardware. We certain can and should use general purpose servers as the control plane. But, I think we really do need special purpose ASICS in the data plane. We just don’t want those ASICs packaged up in an expensive, vertically integrated package.
As you said, Arista is heading in the right direction but we’re probably still a year or so away from getting exactly the solution we’re after. Happy holidays Tinkthank.
jrh@mvdirona.com
A Dell R210 with an Intel dual port 10 gig NIC will set you back $1500. Sure, I’d rather have a Juniper handling routing but at several orders of magnitude more expensive than Dell I’ll stick with the x86 solution.
I’d love to see more open and flexible switching/routing products. Arista is sort of headed in that direction. Unfortunately I think we’re still a couple years away from being able to throw out all our Cxxxx and Jxxxxxx hardware.
Sure, I know an x86 makes a good network appliance. I would love to use them as switch gear but, price performance and power performance makes ASICs look very good for high volume networking. I always prefer general purpose processors but,for high volume repetitive task, custom ASICs win.
James Hamilton
jrh@mvdirona.com
I think there is a point you’re missing the point that those are "appliances". They do a single task unlike x86 servers. BTW, I’m sure you know this well but you can turn any x86 server into a networking appliance if you want.
From Stig "Who knows, maybe vyatta will integrate an OpenFlow controler???"
That would be a step in the right direction. What would be really cool is Vyatta ported to run on OpenFlow so that it could run on NEC, Toroki, and the others currently working on adding OpenFlow support to their routers.
James Hamilton
jrh@mvdirona.com
> I love pure software solutions but for massively repetitive tasks, hardware wins.
Who knows, maybe vyatta will integrate an OpenFlow controler???
Thanks for the comment Stig. You can indeed use x86 hardware for core routing but high-volume, commodity priced ASICs such as Broadcom yield better price and power performance. I love pure software solutions but for massively repetitive tasks, hardware wins.
James Hamilton
jrh@mvdirona.com
Steve, your right that Cisco can run IOS on x86 but that won’t help us with this quest. We want a multi-source, non-vertically integrated stack.
James Hamilton
jrh@mvdirona.com
Check this out. Intel published a paper showing that off the shelf x86 hardware running open source vyatta can do 10G line-rate: http://kellyherrell.wordpress.com/2009/12/18/intel-takes-vyatta-to-10gig
I believe that Cisco can actually run IOS on x86 hardware; its a trick they use so they can simulate complex networks: host cisco VMs under the VM stack of choice, set up complex interconnects, route packets, see what happens. Good for replicating the obscure support calls, as long as they aren’t the ones that only crop up after the third petabyte of traffic.