Last week Fortune asked Mark Hurd, Oracle co-CEO, how Oracle was going to compete in cloud computing when their capital spending came in at $1.7B whereas the aggregate spending of the three cloud players was $31B. Essentially the question was, if you assume the big three are spending roughly equally, how can $1.7B compete with more than $10B when it comes to serving customers? It’s a pretty good question and Mark’s answer was an interesting one “If I have two-times faster computers, I don’t need as many data centers. If I can speed up the database, maybe I need one fourth as may data centers.”
Of course, I don’t believe that Oracle has, or will ever get, servers 2x faster than the big three cloud providers. I also would argue that “speeding up the database” isn’t something Oracle is uniquely positioned to offer. All major cloud providers have deep database investments but, ignoring that, extraordinary database performance won’t change most of the factors that force successful cloud providers to offer a large multi-national data center footprint to serve the world. Still, Hurd’s offhand comment raises the interesting question of how many data centers will be required by successful international cloud service providers.
I’ll argue the number is considerably bigger than that deployed by even the largest providers today. Yes this represents massive cost given that even a medium sized data center will likely exceed $200m. All the providers are very focused on cost and none want to open the massive number of facilities I predict, so let’s look deeper at the myriad of drivers for large data center counts.
*N+1 Redundancy: The most efficient number of data centers per region is one. There are some scaling gains in having a single, very large facility. But one facility will have some very serious and difficult-to-avoid full-facility fault modes like flood and, to a lesser extent, fire. It’s absolutely necessary to have two independent facilities per region and it’s actually much more efficient and easy to manage with three. 2+1 redundancy is cheaper than 1+1 and, when there are 3 facilities, a single facility can experience a fault without eliminating all redundancy from the system. Consequently, whenever AWS goes into a new region, it’s usual that three new facilities be opened rather than just one with some racks on different power domains.
*Too Big to Fail: Even when building three new data centers when opening up a new region, there are some very good reasons to have more than three data centers as a region grows. There is some absolute data center size where the facility becomes “too big to fail.” This line is gray and open to debate but the limiting factor is how big of a facility can an operator lose before the lost resources and the massive network access pattern changes on failure can’t be hidden from customers. AWS can easily build 100-megawatt facilities, but the cost savings from scaling a single facility without bound are logarithmic, whereas the negative impact of blast radius is linear. When facing seriously sub-linear gains for linear risk, it makes sense to cap the maximum facility size. Over time this cap may change as technology evolves but AWS currently elects to build right around 32MW. If we instead built to 100MW and just pocketed the slight gains, it’s unlikely anyone would notice. But there is a slim chance of full-facility fault, so we elect to limit the blast radius in our current builds to around 32MW.
These groupings of multiple data centers in a redundancy group are often referred to as a region. As the region scales, to avoid allowing any of the facilities that make up the region to become too big to fail, the number of data centers can easily escalate to far beyond ten. AWS already has regions scaled far beyond 10 data centers.
What factors drive a large scale operator to offer more than a single region and how big might this number of regions get for successful international operators? Clearly the most efficient number of regions is one covering the entire planet just as one is the most efficient number of data centers if other factors are ignored. There are some significant scaling cost gains that can be achieved by only deploying a single region.
*Blast Radius: Just as we discovered that a single facility eventually gets too big to fail, the same thing happens with a very large, mega-region. If an operator were to concentrate their world-wide capacity in a single region it would quickly become too big to fail.
I’m proud to say that AWS hasn’t had a regional failure in recent history but the industry continues to see them rarely. They have never been common but they still are within the realm of possibility, so a single region deployment model doesn’t seem ideal for customers. The mega region would also suffer from decaying economics where, just as was the case in the single large data center, the gains from scaling become ever smaller while the downside risks continue to climb. Eventually the incremental cost reductions of scaling the region become quite small while the downside risk continues to escalate.
The mega-region downside risks can be at least partially mitigated by essentially dividing the region up into smaller independent regions but this increases costs and further decreases the scaling gains. Eventually it just make better sense to offer customers alternative regions rather than attempting to scale a single region and the argument in favor of multiple regions become even stronger when other factors are considered.
*Latency and the Speed of Light: The speed of light remains hard to exceed and the round trip time just across North America is nearly 100 ms (Why are there data centers in NY, Hong Kong, and Tokyo). Low latency is a very important success factor in many industries so, for latency reasons alone, the world will not be well served by a single data center or a single region.
Actually it turns out that the speed of light in fiber is about 30% less than the speed of light in other media so it actually is possible to run faster (Communicating data beyond the speed of light). But, without a more fundamental solution to the speed of light problem, many regions are the only practical way to effectively serve the entire planet for many workloads.
There are many factors beyond latency that will push cloud providers to offer a large number of regions and I’m going to argue that latency is not the prime driver of very large numbers of regions. If latency was the only driver the number of required regions would likely be in the 30 to 100 range. Akamai, the world leading Content Distribution Network (CDN), reports more than 1,500 PoPs (Points of Presence) but many experts see them 10x bigger than would be strictly required by latency. Another major CDN, Limelight, reports more than 80 PoPs. This number is closer to the one I would come up with for the number of PoPs required if latency was the only concern. However, latency isn’t the only concern and the upward pressure from other factors appears to dominate latency.
*Networking Ecosystem Inefficiencies: The world telecom market is a bit of a mess with many regions being served by state sponsored agents, monopolies, or a small number of providers that, for a variety of reasons, don’t compete efficiently. Many regions are underserved by providers that have trouble with the capital investment to roll out the needed capacity. Some providers lack the technical ability to roll out capacity at the needed rate. All these factors conspire to produce more than an order of magnitude difference in cost between the (sort of) competitive US market and some other important world-wide markets.
Imagine a $20,000 car in one market costing far more than $200,000 in another market. That’s where we are in the network transit world. This is one of the reasons why all the major cloud providers have private world-wide networks. This is a sensible step and certainly does help but it doesn’t fully address the market inefficiencies around last-mile networks. Most users are only served by a single access network and these last-mile network providers often can’t or don’t own the interconnection networks that link different access networks together. Each access network must be reached by all cloud providers and each of these access networks themselves face a challenge with sometimes unreasonable interconnection fees that increase their costs, especially for video content.
Netflix took an interesting approach to the access network cost problem. Their approach helps Netflix customers and, at the same time, helps access networks serve customers better. Netflix offers to place caching servers (essentially Netflix-specific CDN nodes) in the central offices of access networks. This allows the access network to avoid having to pay the cost to their transit providers to move the bits required to serve their Netflix customers. This also gives the customers of these access networks a potentially higher quality of service (for Netflix content). A further advantage for Netflix is in reducing the Netflix dependence on the large transit providers, it reduces the control these transit providers have over Netflix and Netflix customers. This was a brilliant move and it’s another data point on how many points of presence might be required to serve the world. Netflix reports they have close to 1,000 separate locations around the world.
*Social and Political Factors: We have seen good reason to have order 10^3 regions to deliver the latency required by the most demanding customers. We have also looked at economic anomalies in networking costs requiring O(10^3) regions to fully serve the world economically. What we haven’t talked about yet are the potentially more important social and political factors. Some cloud computing users really want to serve their customers from local data centers and this will impact their cloud provider choices. In addition, some national jurisdictions will put in place legal restrictions than make it difficult to fully serve the market without a local region. Even within a single nation, there will sometimes be local government restrictions that won’t allow certain types of data to be housed outside of their jurisdiction. Even within the same country won’t meet the needs of all customers and political bodies. These social and political drivers again require O(10^3) points of presence and perhaps that many full regions.
As the percentage of servers-side computing hosted in the cloud swings closer to 100%, the above factors will cause the largest of the international cloud providers to have between several hundred to as many as a thousand regions. Each region will require at least three data centers and the largest will run tens of independent facilities. Taking both the number of regions and the number of data centers required in each of these regions into account argues the total data center count of the world largest cloud operators will rise from the current O(10^2) to O(10^5).
It may be the case that there will be many regional cloud providers rather than a small group of international providers. I can see arguments and factors supporting both outcomes but, whatever the outcome, the number of world-wide cloud data centers will far exceed O(10^5) and these will be medium to large data centers. When a competitor argues that fast computers or databases will save them from this outcome, don’t believe it.
Oracle is hardly unique in having their own semiconductor team. Amazon does custom ASICs, Google acquired an ARM team and has done custom ASIC for machine learning. Microsoft has done significant work with FPGAs and is also an ARM licensee. All the big players have major custom hardware investments underway and some are even doing custom ASICs. It’s hard to call which company is delivering the most customer value from these investments, but it certainly doesn’t look like Oracle is ahead.
We will all work hard to eliminate every penny of unneeded infrastructure investment, but there will be no escaping the massive data center counts outlined here nor the billions these deployments will cost. There is no short cut and the only way to achieve excellent world-wide cloud services is to deploy at massive scale.
I wonder if the data centre system could be made to be more cost/energy efficient by having several high latency data centres spread around the world where renewable energy is cheap a many smaller readily responding, low latency centres in all the main regions.
The low latency centres could respond almost immediately to requests such as the start of a movie stream, buffer a minute of footage or even less and then hand off the remaining data request to a high latency server near a solar farm which could be on the other side of the globe. As long as the latency period is covered it should be fine.
Yes, that can be done. It’s a lot of work but, as we engineer data centers to reduce cooling costs and make them overall more electrically efficient, the financial upside to do these optimizations goes down. For most customers, it’s not worth the opportunity cost. But for compute intensive workloads like Machine Learning training and cyrpto mining, the gains are there and the workloads aren’t particularly latency sensitive to any other part of the world so these workload placements are being influence by economics much as you suggest.
Just imagine “solar-spot” instances reporting you that next 3 days in that region it will be nasty and you cannot continue
Hi James,
Great article! Coming from the International Relations field, I’m a sort of interested observer of the data center industry and this post helped me massively. I’m hoping you’re still checking your website as I have a question:
When building outside the US, what was it like working with foreign governments? What were the obstacles?
I’m always fascinated by the interactions between the public and private space, and the DC industry seems to touch on a lot of those (i.e. energy markets, teleco networks, FDI).
Thanks and all the best
Deploying data centers all over the planet is a complex task where many different dimensions, some of which appear to conflict, need to be balanced. Getting this right and delivering builds on time is truly challenging work. It’s not my area of expertise but I’m impressed with what the team continues to be able to deliver.
I always see a physical layer or layer zero vulnerability from our existing optical fiber architecture that could also be improved upon. I now we have talked end-to-end crypto and block-chain, but elimination of physical taps that stop data theft and eavesdropping has utility in highly unsecured spans….the lowly optical fiber vendor….
Doesn’t full link encryption fully solve that one Gary?
Interesting that you’ve made the comment “Of course, I don’t believe that Oracle has, or will ever get, servers 2x faster than the big three cloud providers”, yet looking at all the recent reviews on performance, it seems that OracleCloud is indeed significantly faster & even cheaper.
And does AWS offer the equivalent technologies to Exadata as a service? Heres a quote “running an Oracle Database on Oracle’s Cloud Infrastructure resulted in superior performance and achieved significant cost savings compared to running the same Oracle Database on AWS.” https://www.avmconsulting.net/single-post/2018/05/04/Oracle-Cloud-OCI-Benchmarking-Oracles-DBaaS-against-RDS—A-Performance-Comparison—Part-II http://www.storagereview.com/oracle_cloud_infrastructure_compute_bare_metal_instances_review https://www.accenture.com/t20161013T060358Z__w__/us-en/_acnmedia/PDF-34/Accenture-Oracle-Cloud-Performance-Test-October2016.pdf#zoom=50
Phil said “Interesting that you’ve made the comment “Of course, I don’t believe that Oracle has, or will ever get, servers 2x faster than the big three cloud providers”, yet looking at all the recent reviews on performance, it seems that OracleCloud is indeed significantly faster & even cheaper.”
No, Oracle servers aren’t really 2x faster than the big 3 cloud leaders, I still don’t see that as a likely outcome in any reasonable time horizon and, having competed with them for nearly 30 years, I’ll point out that lower cost, better value, or even customer friendly aren’t frequent comments when Oracle is discussed :-).
This is a false study that is produced by an Oracle partner. Accenture is also an Oracle partner (they are also an AWS partner, but draw far more income from their Oracle partnership). This study, in particular, does not compare apples to apples in Linux or the hardware. All of the studies that Oracle points to invariably end up being studies from biased Oracle sources. Oracle has a culture of lying where lying is constant in the sales process. That lying is extended to comments and to partners who mindlessly repeat Oracle marketing talking points.
When you say multiple Data centers in a region in AWS , are you referring to AZs
Because as per my understanding even a AZ will be made of cluster of data centers .. am i right James ?
A region needs to include multiple, independent AZs for redundancy. No two AZs should be in the same building. An AZ must be at least one building but could grow to be multiple buildings as you point out Venkat.
Thanks for the response James..
Hello James,
if you speak about redundancy are these resources in hot-standby or being used for normal operations ?
All resources should be active/active. If you don’t test them (constantly), they don’t work when you need them. Active/passive may start out working but soon enough, some software upgrade is done on only one side or some config change is only made on one and the other stops working but you won’t know until you need it in an active/passive config.
thanks, that’s what I assumed. I just was wondering if you would schedule user workloads (which I meant with “normal operations”)
Yes, all AZ are all in use at the same time so we are confident they all are working correctly. Customers that chose to architect there apps for availability and take full advantage of the multiple AZ will have the workload running active/active over at least 3 AZs and have sufficient capacity such that they can lose an AZ and still operate without customer impact. This is a great model in two but it gets increasingly efficient for customers as the number AZs goes up since having the capacity to fail a full AZ is only 1/3 at 3, 1/4 at 4, etc.
Hi James
I’ve become confused: 10 the power of 5 = 100,000 datacenters which is astonishing. Elsewhere, in your reply to Aaron, you say 10K. I assume the latter? Can you clarify, thanks.
Each operator needs O(10^3) regions. Each region requires at least 3 and may have as many as 10 facilities. There will be other points of presence as well as these full regions. Expect O(10^4) from each of the major operators. How many successful international operators do you think there will be.
I would argue that the higher up the abstraction chain an offering is made, the more differentiation possible and the more successful competitors their might be. Simple commodities tend to have few competitors while complex offerings tend to have many successful solutions. On that argument, I would expect at least 10 successful cloud operators.
However, there are some counter examples that could argue for a smaller number of successful competitors. Airplanes are complex machines where lots of differentiation is possible and yet there are only two major players at this time. We’re on the brink of seeing a third player in market. Very capital intensive industries often have fewer competitors
Using this last factor you might end up expecting O(10^4) facilities world wide. My expectation is the number of competitors will be higher due to regional preferences, a wide variety of different service offerings possible, and the diversity of higher level services. Consequently, the number of facilities could be as high as O(10^5) but, if you assume a smaller number of successful competitors, the number might come in as low as O(10^4). Still a fast number.
Interesting, I have been thinking on a similar line as Mark Hurd for quite some time. It is nice to know I am not the only one.
If we look at the future in 5 years time frame.
Moore Law’s isn’t dead ( yet ), 10nm is on track, 7nm is coming. We are 90% certain we will get these two node from Intel in the next 5 years. I am sure Intel will get 5nm out, just not certain it will be in the 5 years time frame.
We have stacked Memory, or DDR5, either way bandwidth or capacity is a solved issue, just a matter of cost.
The DRAM and NAND industry has been enjoying some healthy profits, all the players have 3D NAND on their Roadmap. The Chinese have invested tens of billions into the industry to hopefully have 50% of their NAND and DRAM consumed to be manufactured within its country.
This will happen sometime in 2018 / 2019. While these wont be state of the art DRAM or NAND. Expect the price to stabilize or drop.
We have Optane today, and things will likely further improve as this is still a first gen product. But it already offer huge benefits for Database usage.
GPGPU, or Database on GPU is finally taking shape. And it offers 5x to 20x performance. we could expect this to mature and finally taking mainstream in the next few years.
So we could expect 4x CPU Core, 4X Memory capacity, 10x Latency improvement with Optane over SSD, SSD price getting cheaper, 5x Improve with GPGPU Database, and scaling with 4x transistor Density to 20x.
And I am pretty sure we still have many Software inefficiency to improve on.
So in terms of Database, the same rack in 5 years time could have 10x the performance.
Will Oracle have 10x the customers or 10x its cloud usage in 5 years time?
Google and Amazon is a little different since the near infinite amount of computing power required for AI. But a similar question could also be ask, just when will the curve of computing performance hit the spot where building Datacentre no longer make sense. I am sure China and India have plenty more to grow, likely in the 5 – 10x range. But US and Europe?
Your break down on performance increases for database seems plausible but difficult Ed. Our collective jobs is make sure those predictions come true and I don’t see it as unreasonable. But database is a small part of all the gear in a data center and improving database is useful but doesn’t have much impact on the capital investment needed to adequately serve the cloud computing market segment. All the social, political, and telco market economics reasons forcing regional builds stay the same with database 10x faster or not. In fact, those requirements stay the same even if all servers are made 10x faster. The availability argument to build out multiple facilities in each region still look the same with 10x faster database and even 10x faster servers in general wouldn’t change it.
I’m all for faster and I expect most of your predictions will come true. Some perhaps on a little longer time frame but I generally agree. Nonetheless, I don’t see speeding up database moving the needle on infrastructure costs required by a cloud provider to properly serve a world-wide customer base. If we assume the speed discoveries apply to all servers, many but not all of the arguments still apply. There would certainly be a reduction in costs on this model but the point of my write up is it still won’t come close to supporting a 1/10th reduction in overall infrastructure spending. Even with the very aggressive assumptions in speed up and the schedule under which it is achieved, I can’t find a way to make the Oracle 1/10th investment in data center infrastructure work.
Mr. HamiIton, excellent breakdown on the existing QoS & Model but think one thing missed is the financial, operational, technical, management DC replacement requirements of the existing workloads (forget about Industry 4.0 workloads) in worldwide computing from a) global enterprise customers (G5000) b) regional/national enterprise customers 100,000 largest enterprise past the G5K. c) Tech 1000, D) everybody else web:).
The existing cloud workloads are a small fraction of (5% ?) of the global workloads that the cloud DC space will have to handle. If you factor in 3-4x every 10yrs in global workload and the fact its taken 10 years to get the first 5% on the cloud the scale out requirements are massive. Maybe 50-100x the next 20 years. If you add Industry 4.0 that could be its own 10-20x.
If we factor all cool, proven, unproven server, network, management, stack devops tooling, n-tier stacks, ML, serverless, microservices, etc..) maybe we get a 10x improvement. We are assuming we stay in the traditional architecture not Tim Berners Lee Decentralized Web which would blow everything up again. If we assume we are building a DC model to replace all existing DC’s for legacy, now, short future, Industry 4.0 future.
The existing 8.6 million data centers (7m are crap legacy closets that will lift & shift) & 1+ million are enterprise mid-sized lame DC’s that will consolidate & lift and shift) and 400k (are large enterprise nightmare configs that will flop their lift & shifts over 10 years) & the rest are the Tech 1000 (75-90% are lame but are supported by their “special business models”:) now with all this moving to the cloud this 2 billion sq. feet of DC today maybe thats 500m on a “clean DC model” but if the above requirements are 10-100x the next 20 years where is that capacity to get to 5-10 billion sq. feet.? With this the top 3 are going to need 5-10k DC’s in 200 countries each it starts looking like the auto industry?
Aaron presented a thoughtful analysis and predicted 5 to 10k DC in 200 countries. My take was 10k. Both estimates are remarkably similar.
My key point is that nobody is going to offer great cloud service while hoping to be able to spend 1/10th the capital outlay and run with a far smaller world-wide infrastructure footprint.
James, whats scary is the need Tier 1’s to own the scaled “long haul” networks(at least 10-25) of dark fiber which collides with national policy in at the top 50 countries (telco powers) the next 150 can be rammed as they get free rider benefits of the super mega cloud players investment. The risk is the 10-20 year slow slog of getting support from those top 50 countries telco policy/politics regs/legs. This article is a 2+ years old but has a nice breakout of the volumes that make modern Tier 1 DC…
http://www.datacenterknowledge.com/archives/2014/10/15/how-is-a-mega-data-center-different-from-a-massive-one/
It’s true that international telecommunications is a complex web of different constraints and regulations across many different jurisdictions.
This is an excellent and thoughtful analysis, as always. Mark Hurd’s initial point about server performance improvements does raise some interesting questions, though. There is a fairly strong case to be made that, while Moore’s Law is slowing down, energy performance per compute/storage unit, will eventually start to advance dramatically. That, it turn, will enable much, much higher compute density per rack for the same amount of power/heat. So, it might be possible….admittedly not in the next five years – maybe ten – to start to build smaller datacenters – if not necessarily fewer. That might at least make building all these datacenters cheaper. Of course, this is also prone to Jevon’s Law, so we might just find to ways to suck up that power.
I would argue that density gains are largely independent of the pace of Moore’s law. Density gains are driven by two primary factors. The first is what I call hand waving economics. 10 years ago the industry got over focused on density and the result were massively expensive blade servers with incredible densities but actually fairly poor price/performance. These systems were expensive to cool. This first factor, hand waving economics, doesn’t seem real but it has driven many customers to buy massively dense server racks.
The mega-operators are also driven towards density by the economics of improved density. Floor space has value so density does continue to climb at all the mega-operators. What I find interesting is this density growth is remarkably slow because it is driven by economics and the economics favoring density are much less powerful than many think. After server hardware the dominant cost in the data center is power distribution and cooling equipment. Somewhat behind that comes the cost of the actual power itself. Way behind that comes the cost of real-estate.
Using these economics, it makes no sense to spend very valuable power, power distribution equipment, and cooling equipment in order to save relatively inexpensive real estate. It’s this tension that causes mega-operator server density to climb more slowly than the OEM computer market driven by hand waving economics. However, real estate does have a cost and, if you can improve density without spending more on power distribution, mechanical systems, and power, then of course you should. Server density improvements at the mega operators is driven by economics and density does continue to go up but it goes up more slowly than the OEM market.
There are exceptions where higher density does really pay. Floor space in Hong Kong, New York, and servers in high value carrier hotels and other communications nexus, does tend to higher. In this facilities, more density makes economic sense. Only a tiny fraction of the overall mega-operator footprint is in these facilities but, for servers placed in these locations, the value of floor space is slightly higher. However, even in these locations, some of the hyper dense OEM servers still don’t make economic sense.
My take is the economics around density are largely independent of the pace of Moore’s law. But I still agree with your premise that power per sq ft will continue to climb and, therefore, the absolute size of, say, a 32MW facility could be reduced.
One of the ways I explore the impact of expected future change is to assume the change is unreasonably large and then think through the impact. Let’s do that with real estate and explore what happens if density doubles and critical floor space is halved. Because real estate is way down below 10% of the overall cost of a data center (see //perspectives.mvdirona.com/2010/09/overall-data-center-costs/), this hypothetical increase of density by a factor of 2 has a less than 5% reduction in overall costs. It matters, certainly I’m always excited to chase even 1% gains, but it’s not a game changing number and certainly isn’t one that will allow a build out that fully supports customers at 1/10th the overall cost.
My key argument here is that, if you take any reasonable assumption and investigate the gain, it’s hard to find any change that will allow an operator to serve customers with fewer regions. There may be some changes that might reduce the number of facilities that make up a region but none of these levers have the power to give a 10x gain or, worded the other way around, I don’t see a way to spend 1/10th that which competitors spend and yet still offer customers a great service. We are all deeply invested in making gains in capital inefficiencies but none are going to allow an operator to spend at 1/10th that of the leaders and yet still have a competitive service.
This has been, without a doubt, one of the richest, most thoughtful threads I’ve read in a very long time based on James’s original post. I had actually dismissed Hurd’s comments as being Oracle hubris.
Sorry, but what’s the ‘O’ in the data centre formulae?
Sorry, it’s just short form for saying order of magnitude. So, for example, O(10^3) is on the order of 1,000.
It’s not short form. It’s 7 characters to represent 4 (5 if you include the comma)
Sorry to be a pedant, but the full phrase is “on the order of 1,000” and not just “1,000” itself, so I’d still consider it short form.
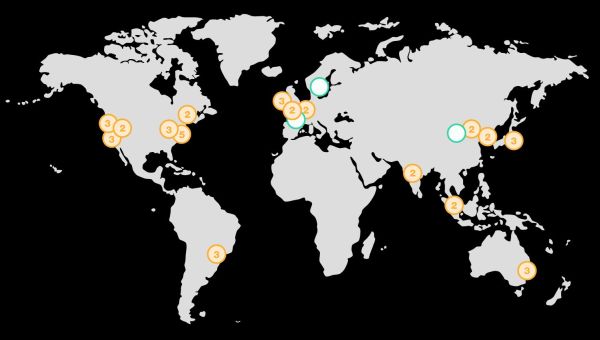
Interesting read but seems fairly US-centric. With the bulk of population growth coming from outside the US/EU the little map shown here looks like something form a Gentlemen’s club discussion in the last century no? Netflix has just announced they will build in Russia, a number of Chinese players already have growing platforms, then we have India, S America, Africa. Nigeria has 140m pop, Ethiopia over 90m, China adds 85m new Internet users a year..surely that’s where the bulk of the next wave of DCs will be?
Yes, of course Guy world growth will be massive. That’s the reason why the article starts with a picture of the entire planet rather than a one of the United States.
As much as I agree with you that world wide growth will be massive. A point where we may not agree is that the US growth will be massive as well. It’s day 1 in the US market with most growth still in front of us and yet the world-wide markets are even larger.
I think Mr. Hurd is probably referring to Oracle’s SPARC CPUs ( which they inherited from the Sun Micro acquisition). Remember Sun machines used to power the dotcom boom ?
So , they have been developing cutting edge silicon for decades , unlike AWS, Google or Microsoft. they may have a real leg up in the case – only time will tell.
SPARC, if it ever was competitive, hasn’t been for years. Oracle’s ownership hasn’t changed that and has created some serious problems as well. Their T4 were nightmares that never actually did what they promised. Their “red stack” PR campaign rang entirely hollow to many customers as their own people didn’t understand the technologies they claimed to support for enterprise customers. Their engineered systems are mostly based on commodity hardware, and recent reports say they’re laying off people from SPARC, Solaris, or both. Their best-selling product is spin…
Hard to believe if you look at the following web sites .
https://en.wikipedia.org/wiki/SPARC
http://www.oracle.com/us/products/servers-storage/edison-sparc-s7-wp-3395977.pdf
There deffinitely was a time when SPARC was the best price/performing hardware out there but that was a very long time ago and many of those engineers have moved on. Certainly those I knew have long sinced left the company. Add, just about all of their customers are have moved on to better price/performing solutions as well.
They are claiming better performance for DB and Java workloads. The SPARC cores apparently run at 4.4 GHz. Also, as these are their own chips , they get them at cost with 0 margin !.
Years ago, IBM had the system to beat and they continue to claim the superiority of the Z-series. Nonetheless, most of the market has moved on. Sun was an incredible systems company with some of the people I still respect most in this industry. The E10k was amazing engineering challenge to take on and Niagra was a very impressive processor. Nonetheless, most of the market has moved on. All the mega operators have been able to buy Sparc systems from Sun and Oracle but that hasn’t been the outcome. I’m pretty sure that if these systems would have been offered at zero margin, it wouldn’t have change history.
When the market moves on, the volumes move on, it’s volumes that support the R&D investment stream that keep a product on top, and without customers and deep investments, the best engineers move on as well. In our world, volume always wins which is one of the reasons why it’s worth watching mobile R&D very closely. Many ideas start in the client or mobile segments and end up used in servers so it’s worth us all watching mobile particularly carefully.
James, this is Oracle we are talking about, not IBM – 2 very different companies. Given the facts 1) Oracle arguably has the best database technology 2) Sun Micro developed very successful CPUs for decades 3) Oracle latest SRAPC CPU has some metrics better then x86 in some areas 4) Oracle can get the CPUs at cost 4) AWS started a silicon effort about 5 years ago ? 5) AWS has not announced any CPU development yet – CPUs are far more complex then other chips as you know 6) x86 CPUs are the biggest cost of a rack .
Given the above known-known’s and possibly no known-unknowns, where would a rational person put their money ?
You do understand that the decline of SPARC from dominant to lost in the IDC server market share “other” category had nothing to do with AWS or even cloud computing? Customers just stopped buying Sparc believing X86 was a better price performer. The mega-operators are free to buy whatever they want including Sparc but they are also going X86. You may be right that Sparc is going to take it’s single digit market share and retake the market but that wouldn’t be my prediction.Processors, need applications and there just aren’t many application owners targeting Sparc as a first class platform. Let’s you and I look again in 3 to 6 months and see if Sparc server market share is resurging or continuing to decline.
James, fair enough. That is exactly what I said – ‘only time will tell’. Do not leave out ARM servers – I guess cloud computing is going to get lot cheaper !!
Me too Subrata. I’m a huge fan of ARM. Both ARM and some of the processors we were talking about earlier in the conversation, have very small server market share. In ARMs case it is way less than 1%. But what makes ARM interesting to me is they have volume. Back in 2013, the 50 billionth ARM processor was shipped. Volume drives R&D and drops per-part costs. Volume almost always wins in the server world so, yes, ARM is highly interesting and definitely worth watching.
ARM is made even more interesting by de-verticalizing the ecosystem which usually drives more competition and more innovation. In today’s server world there is a single company doing the architecture, specializing the architecture to specific market segments, producing and packaging the parts, and distributing the outcome. In the ARM ecosystem, ARM just does the architecture but many other companies including Qualcomm, Samsung, Apple, and many others take the architecture and produce workload focused designs. The silicon foundry is usually yet another company. Packing and test might be yet another company.
Many companies have ARM architecture licenses and produced workload focused designs. Literally 100s of companies take ARM designs and add additional digital logic or accelerations to produce a final part. In most cases, the fab work is done by yet another company. It’s a vibrant ecosystem with massive innovation and the reasonable margins that come from a competitive marketplace. Even with these systemic advantages and massive volume, there is still considerable challenge in taking this innovation to the server world so success is far from given. Many companies including Qualcomm, Cavium, and APM think they can build a successful server business on ARM. Unfortunately, there are a few others that had announced plans to enter the server market but subsequently failed or left the market. Of course, there are other players that haven’t publicly announced an intention to produce an ARM server part but have work underway.
ARM is by no means assured success in the server market but there are some very capable companies with excellent teams working on it and, in our world, volume just about always wins. ARM is absolutely worth watching.
All blog posts should have a date/time stamp, James! Please add one to yours. My guess for this post (based on the Michael Leonard’s comment) would be 18 April 2017, is that correct?
Good article, by the way!
Tony, the blog software shows date but doesn’t bother to show time. Do you actually care if it was at 2pm or late evening that the post went up? This one was posted at 3:56pm Eastern Daylight Time on 4/18.
I think what Tony means is that the articles do not show the dates at all – so we can’t tell that this article was published on 4/18/17. Unless of course we look at the first comments and guess the date. Thanks for the great article!
Though you can see the date of an article if you go to the home page and find it in the latest posts – there it says the date of the article.
I agree it could be easier to find but the date of each article is on the main blog page: //perspectives.mvdirona.com/. News Magazine, the WordPress template I use for the blog doesn’t also date the individual entries themselves. It probably would be better if it did.
Hey James – always clear eyed perspectives from you – it has been a while, but felt like jumping in here to see if we might crowd source an answer to your articles fundamental question – how many datacenters do we really need??? – I had posted about Hurd’s artilce/interview earlier (see: https://www.linkedin.com/feed/update/urn:li:activity:6258338941733339137/) and while agree with your position, where I gave Oracle some “hope” was in ability to figure out how to take their exisitng, legacy footprint in the Enterprises (which is considerable) and transfer to a “like” environment running on Oracle dbs – if they can do that, they have some hope of “getting into the game” at this stage…BUT, they will not be competative upon the global-utility stage thinking “less is more” – so really two different questions I parsed – one on technical workload trasnsfers (Oracle has some hope) and how much infra is needed to run the 21st century – the latter is what I think is still worth exploring since the models now are becoming more consistent and we have running data for last 10-15yrs to work from to predict the future…:-)
That said, I see an upcoming inflection point, however, as the industrial/enterprises move “online” – think GE to Boeing to GM to Genetech to Ralph Lauren – I do not think the world truly recognizes the upcoming tsunami of demand that is upon us – I call this the digitiaztion of the Enterprise Supply Chains (and everyting in between) – IoT and so much more is at heart of this and will spur an ever steeper slope for infra capacity growth…just autonomous vehicle fleets alone (sliver of what is upon us!)
And yet another wrinkle that will drive up demand – Moore’s law coming to an end – we can not shrink our waffers any more – this will stall capacity gains and increase infra builds over next decade or so until a break thru in compute comes along (is that another article btw??)
So, how do we model this? CPUs + Memory + Disk are driven by overall demand that necessitates so much infra per region and global capacity models are taking shape not unlike electrical grid demand modeling – that wasn’t as accurate in first few decades but has evolved into a fairly predictable utility – internet infra is no different – sooooo, do we model out x 100-300MW facilities per region with y number of smaller cache facilities to get to N number of datacenters – do we use MW as underlying denominator and substitute cpu/mem/disk as an amalgamated numerator to get rough look at how many are needed? would be a fascinating model to up on line and crowd source a solution…:-)
PS – http://finance.yahoo.com/news/global-data-center-construction-market-154300265.html – I think that this under represents growth by a factor of 30-40% in years 3-4+….
Richard, very interesting perspective on the future of the utility computing model. If the region is a nation or a state to remove ambiguities between different vendor models then what is the right metric to report and forecast the needs? Is it CPU Cores, MW, TB, Gbps or workloads? There is a challenge in using just one or few of these metrics to predict future needs esp with serverless compute, caching, real-time vs batch workloads.
Second, if you are a public administrator of such a region how do you distinguish between the needs of residents (consumers) vs businesses (industrial usage) vs public infrastructure (public security, transportation, civic engagement)?
GREAT posting Richard. Super interesting. You brought up three main trends:
1) enterprise foot print has massive value and, for those players such as Microsoft, Oracle, and IBM, this is a huge advantage. If they are smart and leverage this in a way that helps customers, it’s a massive advantage. You are 100% right. I basically have nothing to add on this one.
2) IoT is going to drive massive increase in computing demands partly because of all the deployed devices but mostly the processing of the vast quantities of data that comes from all these sensors. The data is super useful in driving IoT actuators and that’s often the first use but the value of the data asset produced by IoT is way bigger than the value of the real time control systems that will of course be built. My favorite example these days was from a visit I did a bit more than a year ago with Bell Equipment, a mining equipment company. They collect a ton of data with sensors and they can use this data to make better decisions on the truck. For example, as the load is dumped by the truck needs to be stopped but as the load is dumped the truck becomes more stable as the load pours off so it can get underway before it’s complete. That shaves some seconds off each load and it adds up over time. But what is more valuable is all the data sent back on truck utilization, break usage, idling time that can be analyzed to help customers design their mines better, train their operators better, and make better use of their equipment. I agree with you that this will massively change the current server-side requirements for most companies.
3) Moore law comming to an end. On this one I sort of agree but don’t worry much. The end has been near for years. In disk drives we have been near the superparamagnetic limit for years but disks keep improving. We have been at the limits of optical lithography for years but we continue to find ways to get to smaller feature sizes. All these limits are real but they are never as close as they appear and alternatives that allow continued improvement seem to always be found.
One factor you didn’t mention is machine learning. In my opinion, the server side footprint of machine learning will exceed the total footprint of all server side computing in way less than 10 years. Any model you or I have on server side computing is pretty much completely broken. ML will drive such massive growth that it will dwarf all server side computing in aggregate.
R. Goel, I appreciate your point as well. There are many social and political reasons why a region will be required at a given location even when the latency to a nearby region is absolutely fine. It’s technically possible to server the world acceptable latency for most workloads with O(10^2) regions but it simply won’t happen.
@James – yeah, forgot to add ML – spot on again, ML will create yet another step function in demand as more “self aware” systems evolve – now, to bring Mr Musk into this, when do we start to be concerned about self actualizing systems??? :-)
Richard asked “when do we start to be concerned about self actualizing systems?” I’m not sure but I do know that I have always hated when my software systems have done what they want rather than what I thought I wrote :-).
@R Goel – great questions and models we can draw from already are how power utilities do that today – I always harken back to Nic Carr’s book “the big switch” – basically, the idea of a utility has been borne out already and the idea of how to do demand planning, etc., has already been achieved (it has room to improve for sure, but it is still pretty dang good) – but what is different is the idea of a global utility – this is what sits in front of Amazon, Google, & Microsoft – what will it mean to their respective SLA’s when they provide services to cities, states, militaries, schools, business, and consumers – how do you protect the workloads associated with critical care, e.g., hospitals, etc.?? That is something that they have to work out within their SW stacks – the idea of the physical infra, however, as being impervious to down time is not practical – one must have, as James points out, 3 main hubs per region for reliability/cost efficiencies and SW must balance between them – but, how you specify workload SLAs specific to criticality of the workload remains to be seen…but it will be figured out i guarantee it
After reading through this piece and the comments (appreciate the topic immensely BTW), I can’t help but comment on how extremely difficult it is for companies to speculate what the known data center capacity needs would be for their company 2-3 years from now. I am finding that even within a system of known variables, relatively known assumptions and a historical track record such as Facebook, Google, Amazon, IBM, Apple and Microsoft there is still the constant of change. All systems evolve and change… and even those who do have a way of tracking and measuring said capacity growth as it relates to tangible usability metrics (# of users, # of downloads, # of streams, etc.) are subject to the reality that something may disrupt one of the economic drivers and variables underpinning their “future capacity needs” equation. This, coupled by the volume of UNKNOWN variables inside IT departments, processing taking place inside server rooms and closets within commercial office buildings that aren’t even accounted for (shocking how much this exists even today)… I’m left to feel that any attempt to even guess future data center capacity needs is nothing more than the economic models I used to have to create in my college econ classes that only worked inside the vacuum of the classroom. Hence, my 2 cents, when pondering how much data and data processing humanity will end up needing in the future with IoT, BI, AI, ML and technologies and use cases we haven’t even imagined yet likely coming into play over the next few years that may change the entire paradigm of how we currently store, process and deliver data… I’m simply left to answer “More, a lot more… or maybe a whole lot less!”
Hi James,
Just curious, in your opinion which data center design is better. Raised Floor or Slab foundation? Which one does Amazon use and why ?
Either slab or raised floor works equivalently well for cable runs and hot aisle/cold aisle containment so the difference is mostly cost and build times. I prefer slab just due to cost considerations and, with storage racks climbing up over 2,500 lbs slab just looks better and better.
Hi James, great discussion on the potential areas of innovations and the constant. Obviously for the breakthrough among the competition some assumptions in the general thinking may require disruption. I agree with your assertion that the speed of database is too narrow a metric to truly disrupt this market at 10x.
Perhaps, a future discussion on what customers value most among latency, Application/data SLA, cost could provide an interesting insight. If it’s cost than what latency and SLA is sufficient for enterprise workloads?
That’s a super important question and, for most customers, cost is not their primary metric. It’s super important but they first want their data secure, the application available, and the application running well within it’s latency requirements. After the apps is running correctly, reliably, and securely, costs tend to dominate the thinking.
Most customer over spend on performance just to avoid the risk/hassle of having an app that failing due to resource constraint or running too slowly. What exactly is “too slowly?” It depends. Workloads range from hard real time where need complete control of the hardware to soft real time with deadlines ranging from sub-millisecond through to to batch jobs where minutes to hours are not a problem. The shorted schedule end of the spectrum will stay on premise. These can be hard to serve properly from even 1000m away but the vast majority of the world’s workloads have more flexibility.
There is no single SLA or latency that is sufficient for enterprise workloads. They just are all over the board. The only practical way to support them all is to offer alternatives at different price points.
I think there is some misunderstandings here. No doubt Oracle are behind in their IaaS role out but their new data centers are rolled out as regions made up of 3+ data centers. The same strategy as AWS employs today. If you look at Oracle’s IaaS engineering team who designed their architecture, you may find some irony in where they worked previously.
Oracle’s decision to hire from existing successful cloud providers doesn’t seem all that ironic or surprising JG. I’m just arguing that neither that tactic nor any other is going to deliver results at 1/10t the cost of the competition. Arguably, when hiring skills from competitors, one would presume if all other factors were held constant, the results couldn’t be better than those of the competitors.
I’m pretty sure there is no confusion on this one. I’m not arguing that Oracle isn’t deploying data centers in groups of three nor claiming they haven’t made some hires from competitors. I’m just saying those tactics or others won’t magically change the economics of cloud computing. It takes a big and continued investment to deploy a world-wide infrastructure and I don’t know of any solution that yields good results for customers at 1/10th the cost.
I agree with you, Oracle need to be less conservative and roll out more data centers a lot faster. I don’t agree all factors are (or will be) constant. All providers invest deeply at database layer, but Oracle have 30+ years vs AWS Aurora (~2-3 yrs), AWS are far in front in terms of global footprint but perhaps do not have as much of the enterprise market as they would like…. I would like to know what you think off Oracle’s ‘off box virtualization’ (bare metal cloud services) and defer to your far superior knowledge! thanks
I hear you JG on Oracle having a deep history in database. It’s totally true. I don’t accept that AWS doesn’t have same quality of talent but I hear you on Oracle can produce a very high function database product. But, in engineering, you always need to wait for the other shoe to drop. What does it actually cost? Good is only good if it’s good value.
I was lead architect on DB2 for many years and still love the product. I led many of the core engineering teams in SQL Server at point or another and I continue to really like that product. I’ve competed with Oracle for many years so perhaps may not “love” the product but I certainly respect it. Where there is room to look more closely is how does Oracle price their products and how well do they take care of customers. Think of it like a job interview. When you talk to a potential new member of the team and they say they are “excellent team players” or “super innovative”, the first thing I ask for is an example. It rare that someone has no examples of what they really are best at. The best predictor of future results is the history so far. Such is also the case with companies. The best predictor of future pricing tactics is past pricing tactics. Some companies are very motivated to deliver high customer value at prices that approach their costs. Others are very motivated to charge a premium unrelated to costs. I’ve seen companies succeed by both metrics so can’t categorically call either one wrong but, no surprise, as a consumer I have a strong preference.
You asked what I think about off box (bare metal solutions). I love ’em and think everyone will have a competitive offering.
If oracle are only provider offering bare metal today (all be it one region), do you think they have a jump on the competition by being ‘late to the party’?… from my limited knowledge, imho the biggest challenge for aws was always meeting future demand with aging iaas so i’m curious will they be victim of their own success when trying to roll out a bare metal on global scale considering they have such a huge user base on what is aging iaas. I’m curious to see what aws – vmware partnership will produce, will it be something like ravello with L2 networking capability or something more basic that’s the 2 offer already offer today.
The AWS pace of innovation appears to continue to lead the industry. I’ve not seen much evidence of anything slowing. In fact, the numbers suggests AWS continues to ramp up the pace. My 2016 Re:Invent talk showed new features and services at:
2011: 82
2012: 159
2013: 280
2014: 516
and, as I recall, the 2016 number was closing on 800. Things aren’t slowing down.
A coupe of recent talks on AWS infrastructure:
*Innovation at Scale (2014): https://www.youtube.com/watch?v=JIQETrFC_SQ
*Re:Invent 2016: Tuesday Night with James Hamilton (2016): https://www.youtube.com/watch?v=AyOAjFNPAbA&t=32s
yes but there is also the saying, you can prove anything with statistics, how many features have oracle unleashed in 30 years with their DB (millions?) …. i enjoyed your talk, not many keynotes can hold my attention for 90 mins but i watched every minute of yours. I was very skeptical of oracle’s IaaS but this talk impressed me also..
https://www.oracle.com/openworld/on-demand.html?bcid=5138745651001
JG, reasonably argues that statistics can tell us many stories and AWS might not be moving as fast as I describe. Fair enough. Which cloud operators do you think are bringing new features and services to customer faster than the current AWS pace?
I don’t doubt AWS is miles ahead in IaaS right now, I’m wondering why they don’t offer Bare Metal instances, and/or L2 networking functionality (similar to Ravello today). I’m questioning is it easier for a newer entrant to the market to implement bare metal cloud etc ahead of a provider that has huge existing footprint. I guess it’s not a black and white answer
On bare metal, it’s a feature prioritization, security, and alternatives discussion. Bare metal doesn’t have to be black and white. You can get arbitrarily close to bare metal through hypervisor offload, SR-IOV for networking, SR-IOV for networking, etc. Bare metal brings some super challenging security problems like how to prevent BIOS and I/O device firmware attacks, and how do you protect customers from a previous tenant. These exploits are challenging to fully address and it’s an area of security research that isn’t yet fully developed. There are likely many more exploits yet to be found in these firmware and other device attack vectors. Offering bare metal while protecting customers is challenging. The alternative approach of incrementally offloading hypervisor tasks has security advantages and can sufficiently close to bare metal that it’s difficult to see the difference in real world applications.
Both approach will produce very good results and, looking sufficiently far out, I expect the tiny amount of code left in the hypervisor on the move-it-incrementally approach will be moved to the processor making the approaches identical. In the short term, bare metal has a small and decreasing performance advantage with somewhat more security surface area and risk. I don’t see any technical reason why all cloud vendors whether the entered the cloud market early or more recently couldn’t offer bare metal. It’s just a feature priority and performance gain vs security risk decision.
I guess this why oracle admit it is a “big bet”, but where they remain ahead is at database layer but as you said in 2014 “database is hard”
Absolutely support you calling Oracle’s bluff on this one. Especially hosting and running code which exists today (all but a tiny bit of the available revenue).
However, there is a way to build software which drastically reduces the amount of CPU needed to run an application or service which is network or storage intensive. Not talking about High Performance Computing here, that’s not only already tuned, it’s where user space cluster networking was invented decades ago.
Picture the application or service instance, running in what for lack of terminology I’ll call a “sealed container”. When that container was instantiated, it was given memory mapping table entries pointing to (1) the storage it is allowed to access, and (2) infiniband style send/receive queue pairs for the endpoints with which it is allowed to communicate within the data center fault containment zone, which may or may not include router(s) to outside. Mapping tables could be in the style of Gen-Z (www.genzconsortium.org).
The application or service in this sealed container has ways to throw exceptions, signal the control plane, be signaled by the control plane, log statistics, etc. But it fundamentally may not call traditional software stacks or the kernel. Much as a Broadcom Tomahawk can forward 3 billion packets/sec at Layer 3 in roughly the same chip area and power budget an x86 could forward 0.1 billion with DPDK.
This takes an application into the control plane/data plane split which was done for networking decades ago, allowing the application to simply access storage inline (no stack, no kernel crossing, no blocking and releasing the CPU) and to interact with other endpoints in the style fine grain parallelism in supercomputers has for a long time, from user space at extremely low overhead. A Calico like function is performed not inline, but rather by the control plane granting the sealed container access to specific send/receive queue pairs.
All of this is quite academic until we have byte addressable storage class memory chips at the right price per bit, a memory semantic fabric, and suitable tables at the server edge to that fabric to do fine grain checking.
Back to the point at hand: Oracle could have a technology plan to do something like this, and therefore it is not provable that Hurd’s claim was a bluff. However, I do not believe Oracle has the will to make fundamental changes like this, and therefore think you are absolutely correct.
@FStevenChalmers
Steve outlines a future application model that could be hosted far less expensively and posited that it might be the case that Oracle has a plan to achieve this. There are many advancements possible that will lower the cost of hosting a given workload and I think much of what you outline below is credible. However, it will make little difference in the number of regions required. All those arguments remain true even with 10x faster servers. You still need to have at least 3 data centers per region and there are good efficiency arguments in having more than 3 facilities per region (N+1 redundancy savings). More efficient servers certainly are good and certainly lower costs but the primary drivers of more regions and, to a lesser extent, more facilities stays the same regardless of server or application efficiency. These requirements are mostly driven by other factors and the industry is stuck with them no matter what.
But, let’s posit that Oracle might have a plan that will run apps more efficiently. I would argue that the entire industry has this plan and all our spending far more than Oracle at advancing these plans. Of course, engineering success is not predicted by spend and Oracle might find something the rest of the industry can’t find. It’s not a bet I would make by I acknowledge the possibility.
For fun, let’s look a bit at server efficiency. One of the biggest server efficiency levers is actually using the servers that were purchased. Many operators are proud of turning off servers that aren’t in use and the power savings. This is respectable work but the real quality gain is keeping those servers on and monetize the investment by selling workload to run on them. The AWS Spot Instance program is a wonderful way to sell these unused resources at great value to the customer but still at a great price for the operator since any price more than the marginal cost of the power is a gain. Server utilization is a massive cost savings lever.
Steve, focusing on your suggestions for a radically reduce application hosting model, your predictions seem credible. What we usually find with these breakthroughs is they come in 100s of small incremental gains rather than as a single step to a new programming model. There is a tension between a fundamentally new programming model with massive gains vs a very similar programming model with good gains. The former has the largest gains but the latter ends up getting all the apps. Usually, but not always, the gains come as you predict but incrementally rather than as a single step.
Some of the predictions you made are actually deployed in the best facilities today. For example, direct DPDK-like communications where app communications go directly from application space to the network interface is here today with SR-IOV. The same techniques exist but are less broadly deployed for storage again based up on SR-IOV. Persistent memory is also here today in very limited, high cost deployments. As you predict, this will be widely available soon — my prediction is the application world will take a while to learn to exploit this feature so it’ll be a bit slow to get to high volume but I agree it’ll have a massive impact. Another “here today” but in small volumes is custom ASICs and FPGAs doing workload specialized work. Google and Amazon both have customer ASICs doing workload accellertion. Microsoft and Google both have FPGAs doing workload acceleration. AWS even makes FPGAs available for customer workloads. Amazon, Google, and Microsoft make general purpose graphics processors available for GPGPU hosted workloads. Google, Microsoft, and AWS are all ARM licencees and all have some form of ARM based research and development underway. AWS is deploying 100s of thousands of custom ARM processors annually.
There is a lot going on in the big cloud providers around custom hardware and the potential gains are startling. Custom hardware has the potential for 10x workload latency improvements, 10x cost improvements, and 10x power improvements. Custom hardware will have a startling impact on application performance, cost, and power.
But, even with the gains above both already here and predicted, we all still need the same number of regions. The number of data centers in large regions might be reduced marginally but, sadly, none of these gains are going to allow any competitor to spend 1/10s as much as the rest and still compete credibly.
Why “2+1 redundancy is cheaper than 1+1″?
Good question and I probably should have covered that. The most common approach to 1+1 redundancy is the simple approach of running active/passive. This easy to do but has the downside in the common case of rarely testing the backup system. When it comes time to fail to the backup systems, it’ll turn out that there was a misconfiguration, the networking wasn’t fully setup, or the software is one version back, or some other event blocks taking the application load.
The right way to run 1+1 redudancy is active/active where both copies are taking load and actively handling roughly half the traffic. Since both data centers are taking active production load this is more difficult to set up but it’s a design that actually works and produces reliable failovers. The most important thing about active/active is the system is always testing all equipment and, as long as more than 50% of the capacity is reserved, failover is a low risk event. Making failover low risk and requiring little operational overhead allows failover to be triggered with less risk.
This latter advantage is the number one more important component of active/active designs. When a system is clearly broken, it’s easy to make the decision to failover. When all is running well, it’s easy to decide not to failover. What’s hard is the massive gray zone when things aren’t quite running right. You have to decide to failover or not but the facts are not super clear. If failoer does no damage, you can try it without customer risk. Again, if failover does no damage and doesn’t pose customer risk, then more junior operators with less experience can make the decision. The net result is a far more reliable application.
Your specific question was why is 2+1 cheaper than 1+1. In order to run active/active in a 1+1 world you absolutely have to reserve 50% capacity so that failovers can succeed without customer impact. But, if running in three data centers, you only need to reserve 1/3 capacity to allow an entire facility failover. This is how Amazon.com and most of AWS runs.
It turns out the advantage scales well past 3 data centers. If, for example you have 10 facilities the overall tactic of running active across all facilities and reserving enough capacity to tolerate the failure of an entire data center just works better and better. The more facilities you have, the less excess capacity that needs to be reserved for failover.
Anything thoughts you can share around how many DCs per region becomes too big to fail or perhaps too complex to manage? For instance, if you have 10DCs per region and only reserve 10% capacity, if more than 1 DC fails, customers will feel it . There’s also the question of manageability. With 10DCs how do you design power domains? Full isolation seems impractical and expensive but sharing raises the risk of multiple failures. Reserving full, needed capacity doesn’t work business-wise but then again, how many of us insure our homes for 10% of its actual value? This was a hard problem even at the micro level (building small HA clusters) so curious how you think about this at massive scale and what principles you apply (if any) to find the right balance.
Thanks.
That seems like generally the right thought process Joe. When does a region become too big too fail or too big to manage? It’s actually a pretty big number if the approach to redundancy is thoughtful and private, non-oversubscribed networking links are employed.
Managing data centers scales just slightly sub-linear with people so manageability isn’t an issue with scale. Adding facilities in the region actually helps in this dimension. Power isn’t really an issue — it’s best to try to get all facilities on different utility substations or at least different mid-voltage transformers. There is so much redundancy on power that the loss of utility power is almost always hidden behind in-facility power redundancy. The odds of a utility outage impacting a facility is fairly low but it does happen. However, the odds of a utility outage impacting two facilities simultaneously is incredibly unlikely.
Power isn’t much of an issue. Networking is. A well designed region uses all private fiber within the region. This is advisable even for fairly small regions. The operator has to carefully manage capacity during expansion to ensure that they always have the reserve capacity to lose links or a full facility without bandwidth problems. This sounds like an easy procedure to get right but it actually does take some skill to keep up and, of course, the operator has to be willing to spend on capacity they are quite likely never going to use since faults are rare and some major faults incredibly rare.
Assuming that all private networking is used in region (and it should be), then networking doesn’t block growth either. The next big blocker to regional growth is its super important that the region never becomes a material portion of the entire bandwidth in the region. This puts in my opinion, too many customers at risk. Some of this can be mitigated by private backbone links between regions but, the bigger a region gets, the more thought needs to spent on these mega-region specific issues. It’s almost always better both for the operator and for customers to use an alternative region rather than allowing a single region to grow without bounds.
Hi James, just curious…why do most cloud providers have data centers in the same US areas (NW states and VA area) but the central, northern area of North America don’t have as many data center locations? I would think that having redundancy in an area with cooler climate and cheaper land would be beneficial.
The regions are essentially “attracted” to population density and communications hubs. The US East coast has many facilities in the Virginia and New York Areas. The US West Coast has many in California. Once these hubs are covered and they will get covered by most operators, the subsequent choices usually are more diverse. After Virginia and California, AWS opened up Portland, Ohio, and Montreal.
You asked why not choose cooler, more northern locations? The quick answer is that being close to population centers and major communications hubs matters to most operators more than cooling costs. Much of the improvements to data center efficiency over the last decade have been in dropping the mechanical system costs but the cost is still material and, all things being equal, most operators will chose cool climes over hot.