Here’s another innovative application of commodity hardware and innovative software to the high-scale storage problem. MaxiScale focuses on 1) scalable storage, 2) distributed namespace, and 3) commodity hardware.
Today’s announcement: http://www.maxiscale.com/news/newsrelease/092109.
They sell software designed to run on commodity servers with direct attached storage. They run N-way redundancy with a default of 3-way across storage servers to be able to survive disk and server failure. The storage can be accessed via HTTP or via Linux or Windows (2003 and XP) file system calls. The later approach requires a kernel installed device driver and uses a proprietary protocol to communicate back with the filer cluster but has the advantage of directly support local O/S read/write operations. MaxiScale architectural block diagram:
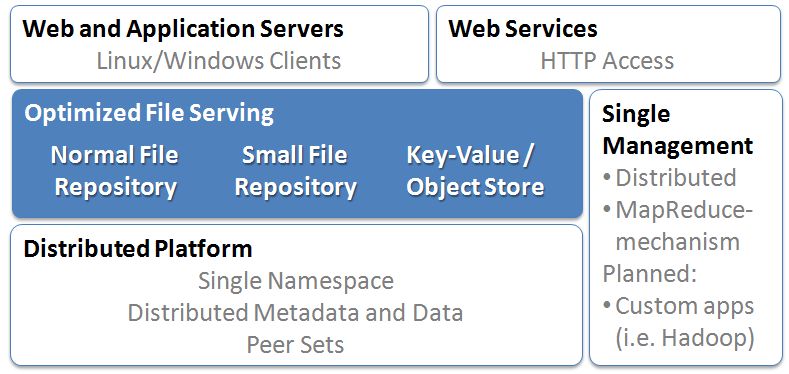
Overall I like the approach of using commodity systems with direct attached storage as the building block for very high scale storage clusters but that is hardly unique. Many companies have head down this path and, generally, it’s the right approach. What caught my interest when I spoke to the MaxiScale team last week was: 1) distributed metadata, 2) MapReduce support, and 3) small file support. Let’s look at each of these major features:
Distributed Metadata
File systems need to maintain a namespace. We need to maintain the directory hierarchy and we need to know where to find the storage blocks that make up the file. In addition, other attributes and security may need to be stored depending upon the implemented file system semantics. This metadata is often stored in large key/value store. The metadata requires at least some synchronization since, for example, you don’t want to create two different objects of the same name at roughly the same time. At high scale, storage servers will be joining and leaving the cluster all the time, so having a central metadata service is a easy approach to the problem. But, as easy as it is to implement a central metadata systems, they bring scaling limits. Eventually the metadata gets too hot and needs to be partitioned. In fairness, it’s amazing how far central metadata can be scaled but eventually hot spots develop and it needs to be partitioned. For example, Google GFS just went down this path: GFS: Evolution on Fast-forward. Partitioning metadata is a fairly well understood problem. What makes it a bit of a challenge is making the metadata system adaptive and able to re-partition when hot spots develop.
MaxiScale took an interesting approach to scaling the metadata. They distributed the metadata servers over the same servers that store the data rather than implement a cluster of dedicated metadata servers. They do this by hashing on the parent directory to find what they call a Peer Set and then, in that particular Peer Set, they look up the object name in the metadata store, find the file block location, and then apply the operation to the blocks in that same Peer Set.
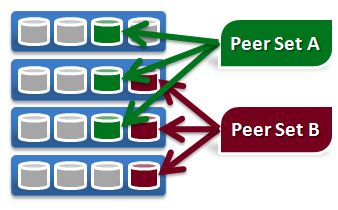
Distributing the metadata over the same Peer Set as the stored data means that each peer set is independent and self-describing. The downside of having a fixed hash over the peer sets is that it’s difficult to cool down an excessively hot peer set by moving objects since the hash is known by all clients.
MapReduce Support
I love the MaxiScale approach to multi-server administration. They need to provide customers the ability to easily maintain multi-server clusters. They could have implemented a separate control plane to manage the all the servers that make up the cluster but, instead, they just use Hadoop and run MapReduce jobs.
All administrative operations are written as simple MapReduce jobs which certainly made the implementation task easier but it’s also a nice, extensible interface to allow customers to write custom administrative operations. And, since MapReduce is available over the cluster, its super easy to write data mining and data analysis jobs. Supporting MapReduce over the storage system is a nice extension of normal filer semantics.
Small File Support
The standard file system access model is to probe the metadata to get the block list and then access the blocks to perform the file operation. In the common case, this will require two I/Os which is fine for large files but the two I/Os can be expensive for small file access. And, since most filers use fixed size blocks and, for efficiency these block size tend to be larger than the average small file, some space is wasted. The common approach to this two problems is to pull small files “up” and rather than store the list of storage blocks in the file metadata, just store the small file. This works fine for small files and avoids both the block fragmentation and the multiple I/O problem on small files. This is what MaxiScale has done as well and they claim single I/O for any small file stored in the system.
More data on the MaxiScale filer: Small Files, Big Headaches: Ensuring Peak Performance
I love solutions based upon low-cost, commodity H/W and application maintained redundancy and what MaxiScale is doing has many of the features I would like to see in a remote filer.
–jrh
James Hamilton
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
Thanks