Earlier this week Clustrix announced a MySQL compatible, scalable database appliance that caught my interest. Key features supported by Clustrix:
· MySQL protocol emulation (MySQL protocol supported so MySQL apps written to the MySQL client libraries just work)
· Hardware appliance delivery package in a 1U package including both NVRAM and disk
· Infiniband interconnect
· Shared nothing, distributed database
· Online operations including alter table add column
I like the idea of adopting a MySQL programming model. But, it’s incredibly hard to be really MySQL compatible unless each node is actually based upon the MySQL execution engine. And it’s usually the case that a shared nothing, clustered DB will bring some programming model constraints. For example, if global secondary indexes aren’t implemented, it’s hard to support uniqueness constraints on non-partition key columns and it’s hard to enforce referential integrity. Global secondary indexes maintenance implies a single insert, update, or delete that would normally only require a single node change would require atomic updates across many nodes in the cluster making updates more expensive and susceptible to more failure modes. Essentially, making a cluster look exactly the same as a single very large machine with all the same characteristics isn’t possible. But, many jobs that can’t be done perfectly are still well worth doing. If Clustrix delivers all they are describing, it should be successful.
I also like the idea of delivering the product as a hardware appliance. It keep the support model simple, reduces install and initial setup complexity, and enables application specific hardware optimizations.
Using Infiniband as a cluster interconnect is a nice choice as well. I believe that 10GigE with RDMA support will provide better price performance than Infiniband but commodity 10GigE volumes and quality RDMA support is still 18 to 24 months away so Inifiband is a good choice for today.
Going with a shared nothing architecture avoids dependence on expensive shared storage area networks and the scaling bottleneck of distributed lock managers. Each node in the cluster is an independent database engine with its own physical (local) metadata, storage engine, lock manager, buffer manager, etc. Each node has full control of the table partitions that reside on that node. Any access to those partitions must go through that node. Essentially, bringing the query to the data rather than the data to the query. This is almost always the right answer and it scales beautifully.
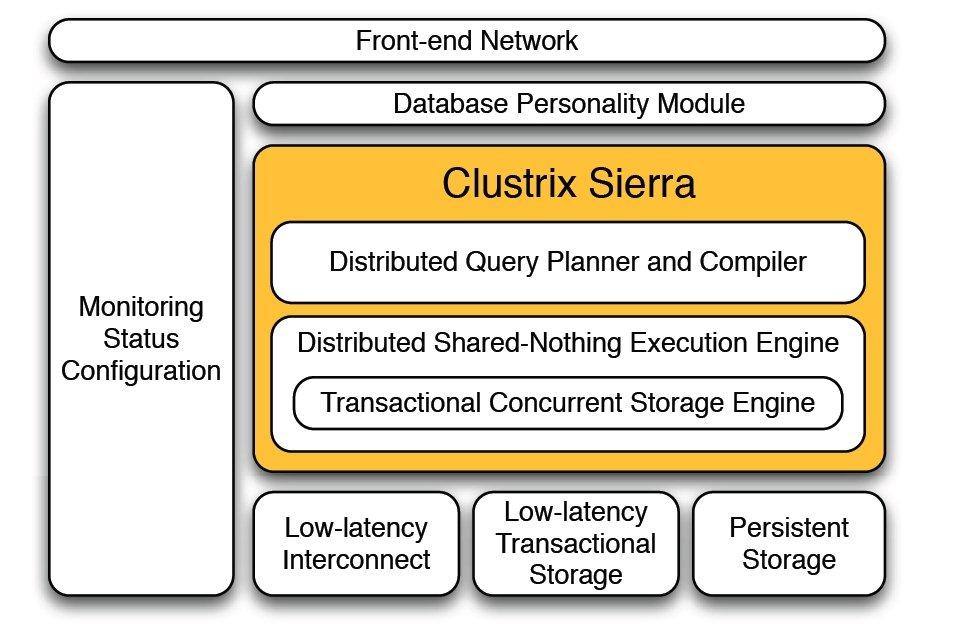
In operation, a client connects to one of the nodes in the cluster and submits a SQL statement. The statement is parsed and compiled. During compilation, the cluster-wide (logical) metadata is accessed as needed and an execution plan is produced. The cluster-wide (logical) metadata is either replicated to all nodes or stored centrally with local caching. The execution plan produced by the query compilation will be run on as many nodes as needed with the constraint that table or index access be on the nodes that house those table or index partitions. Operators higher in the execution plan can run on any node in the cluster. Rows flow between operators that span node boundaries over the infiniband network. The root of the query plan runs on the node where the query was started and the results are returned to client program using the MySQL client protocol
As described, this is a very big engineering project. I’ve worked on teams that have taken exactly this approach and they took several years to get to the first release and even subsequent releases had programming model constraints. I don’t know how far along Clustrix is a this point but I like the approach and I’m looking forward to learning more about their offering.
White paper: Clustrix: A New Approach
Press Release: Clustrix Emerges from Stealth Mode with Industry’s First Clustered DB
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
@jrh "Clustrix is not a shared data system. Like DB2, it’s shared nothing."
That’s exactly what I said – Clustrix is shared nothing, just like DB2’s DPF. Earlier this year, IBM is expanding the DB2 offering to include DB2 pureScale, which is a shared data architecture.
Thanks James and Aaron for the clarification. Some of the doubts have cleared. For the rest, I will have to do some more reading to understand.
~Sudipto
I think this is a good summary of what we do. I wanted to make a couple comments.
We actually do support global secondary indexes. They are implemented as a secondary table that is distributed based on the key being indexed. They are updated atomically with the base rep and all the related replicas of the data with a distributed commit protocol based on Paxos (streamlined because we have a stronger group management protocol than the original Paxos assumed). The commit protocol is tolerant of node failures and is very robust. We fully support unique keys and referential integrity checks. Our cluster does support full MySQL semantics for a very large subset of MySQL. The planning and execution model is general and extensive enough to support full SQL semantics. We chose MySQL as the initial target but don’t be too surprised if we start supporting other dialects in the future.
I kept the examples in the whitepaper simple in order to make the pictures understandable. We do support arbitrarily complex queries including joins, aggregates, sub queries, and a wide variety of functions.
Thanks for the contribution Sudipto. I agree with all you have above except for the inability to do complex transactions over the cluster. This architecture can support complex transactions. There is no magic in that there may be lots of data flowing and cross-server transactions but shared nothing DBs can support arbitrarily complex transactions. Some queries won’t scale wonderfully but the systems can be SQL complete (but many aren’t).
I agree with you it’s not a new invention (Tandem, DB2, & Informix have all been down this path) but it is good engineering if it does all they say it does.
–jrh
jrh@mvdirona.com
No, that is incorrect rxin. Clustrix is not a shared data system. Like DB2, it’s shared nothing.
–jrh
jrh@mvdirona.com
@rxin thx
@ike: Although both DB2 pureScale and Clustrix use infiniband, they are indeed very different breed. PureScale uses infiniband in a shared-data architecture, whereas Clustrix is shared-nothing partition database. pureScale is competing with Oracle RAC offering, while Clustrix is more like DB2 EEE (DPF).
it sounds like DB2’s new feature purescale
Hi James,
I am a PhD student at UCSB, and a regular follower of your blog. My research is somewhat relevant to the clustrix offering, so I quickly went through their whitepaper when Clustrix announcement was made a couple of days back. With all due respect to the designers of the system, from their description, it felt very similar to Key-Value stores in layout, with SQL, transactions, and secondary indices (you can see most of their example queries are on the primary keys, they do not talk about secondary attribute based accesses, also their indices are separate tables, similar to that proposed by the PNUTS folks). But at the end of the day they use distributed transactions for replica and index consistency. Also their example queries in the whitepaper are all simple queries which can be sub-divided into parallel queries/updates and the system just has to guarantee atomicity. But I didn’t get a feel how are they going to address complex transactions, like for instance a standard TPC-C NewOrder transaction, where all relevant data is potentially scattered across multiple nodes (since they do not talk about any intelligent data placement logic) on the cluster, and it is no intuitive how they will avoid distributed concurrency control. In such a scenario, this system seems to be almost a re-incarnation of distributed databases built more than 3 decades back — the only difference being they are applying the concepts on a cluster with low latency and reliable network, rather than a WAN spanning geographical regions.
Since you have spent a fair amount of your time in designing and building these systems, I was wondering what will be your gut feeling on this. I think I am missing the novelty of this design and why this would be successful in the long run. Awaiting your comments.
~Sudipto