While at Microsoft I hosted a weekly talk series called the Enterprise Computing Series (ECS) where I mostly scheduled technical talks on server and high-scale service topics. I said “mostly” because the series occasionally roamed as far afield as having an ex-member of the Ferrari Formula 1 team present. Client-side topics are also occasionally on the list either because I particularly liked the work or technology behind it or thought it was a broadly relevant topic.
The Enterprise Computing Series has an interesting history. It was started by Jim Gray at Tandem. Pat Helland picked up the mantle from Jim and ran it for years before Pat moved to Andy Heller’s Hal Computer Systems. He continued the ECS at HAL and then brought it with him when he joined Microsoft where he continued to run it for years. Pat eventually passed it to me and I hosted the ECS series for 8 or 9 years myself before moving to Amazon Web Services. Ironically when I arrived at Amazon, I found that Pat Helland had again created a series in the same vein as the ECS called the Principals of Amazon (PoA) series.
The PoA series is excellent but it doesn’t include external speakers and is hosted on a fixed day of the week so I occasionally come across a talk that I would like to host at Amazon that doesn’t fit the PoA. For those occasions, the Enterprise Computing Series lives on!
In this ECS talk Ashraf Aboulnaga of the University of Waterloo presented High Availability for Database Systems in Cloud Computing Environments. Ashraf presented two topics, 1) RemusDB: Database high availability using virtualization, and 2) DBECS: Database high availability and availability using eventually consistent cloud storage. The first topic was based upon the VLDB 2011 Best Paper Award “RemusDB: Transparent HighAvailability for Database Systems” by Umar Farooq Minha, Shriram Rajagopalan, Brendan Cully, Ashraf Aboulnaga, Ken Salem, and Andrew Warfield. The second topic is work that is not yet published nor as fully developed.
Focusing on the first paper, they built an active/standby database system using Remus. Remus implements transparent high availability for Xen VMs. It does this by reflecting all writes to memory in the active virtual machine to the non-active, backup VM. Remus keeps the backup VM ready to take over with exactly the same memory state as the primary server. On failover, it can take over with the same memory contents including an already warm cache.
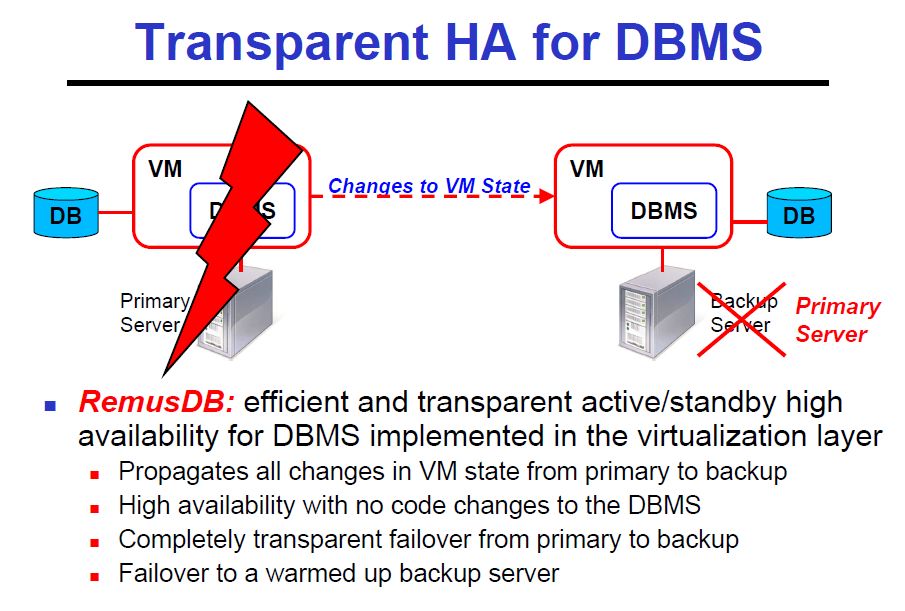
Remus is a simple and easy to understand approach to getting very fast takeover from a primary VM. The challenge is that memory write latencies are a fraction of network latencies so any solution that turns memory write latencies into network write latencies simply will not perform adequately for most workloads. Remus tackles this problem using the expected solution: batching many requests in a single network transfer. By default, every 25msec Remus suspends the primary VM, copies all changed pages to a Dom0 (hypervisor) buffer and the allows the VM to continue. The Dom0 buffer is used to minimized the length of time that the guest VM needs to be suspended but comes at the expense of requiring sufficient Dom0 memory for the largest group of changed pages in 25msec.
Once the guest machine changed pages are copied to Dom0, the primary VM is released from suspend state and the changes just copied to dom0 are then transferred to the secondary system and applied to the ready to run backup VM.
The downsides to the Remus approach are 1) a potentially large dom0 buffer is required and 2) up to 25msec of forward progress can be lost on failover, 3) the checkpoint work consumes considerable resources including time. The time to copy the changed pages may be acceptable but the other overheads are sufficiently high that it is very difficult to host demanding workloads like database workloads on Remus.
The authors tackle this problem but noting that Remus actually does more than is needed for database workloads. Or, worded differently, a Remus optimized for database workloads can dramatically reduce the implementation overhead. They introduced the following optimizations:
· Asynchronous checkpoint compression: Maintain an LRU buffer of recent pages and only ship a delta of these pages. This optimization is based upon the assumption that DB systems modify some pages frequently and typically only change a small part of these pages between checkpoints.
· Disk read tracking: don’t mark pages read from disk as dirty since they are already available to the backup server via an I/O
· Memory deprotection: allows DB to declare regions of memory that don’t need to be replicated. This turned out not to be as powerful an optimization as the others and had the further downside of requiring database engine changes
· Network optimization/Commit protection: Remus buffers every outgoing network packet to ensure clients never see the results of unsafe execution but this increases latency by not allowing any response back to the client until the next Remus checkpoint. Because DBs can fail and transactions can be aborted, they DB optimization is to send all packets back to client in real time except for commit, abort, or other database transaction state changing operations. On failover, any client in an unprotected network state (changes have been sent since the last checkpoint) has the transaction failed. A correct client will re-run the transaction and proceed without issue.
What was achieved is Remus, fast-failover protection for database workloads and far lower replication overhead. The authors used the database transaction benchmark TPC-C to show that Remus with DB optimizations has all the protection of Remus but with roughly 1/10th the overhead.
Slides: http://mvdirona.com/jrh/TalksAndPapers/AshrafAboulnaga20111114.pdf
VLDB Paper: http://www.cs.uwaterloo.ca/~ashraf/pubs/pvldb11remusdb.pdf
–jrh
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com