Archive For The “Ramblings” Category

The best way to hire great women is to have great women at the top of the company. IBM is a lot stronger for employing Pat Selinger for 29 years . She invented the relational database cost-based optimizer, a technology that sees continued use in relational database management systems today. But more than being a great technologist,…
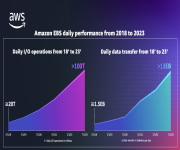
Just after joining Amazon Web Services in 2009, I met with Andrew Certain, at that time a senior engineer on the Amazon Elastic Block Store (Amazon EBS) team, to get into the details on how EBS was implemented and what plans were looking forward. Andrew took me through the details of this remote block storage…
One of the Amazon Operations teams was hosting a conference for Product Managers in their organization and they asked a few of us to record a 1-minute video of what we each view as important attributes of a Product Panager. My take is below with a link to the video. The best Product Managers push…

I introduced the 2022 National Academy of Engineering Frontiers of Engineering conference on September 21st. The National Academy of Engineering was founded in 1964 is part of The National Academies of Sciences, Engineering, and Medicine. The NAE operates under the same congressional act of incorporation that established the National Academy of Sciences, signed in 1863 by President…

August 25th, 2021 marks the 15-year anniversary for EC2. Contemplating the anniversary has me thinking back to when I first got involved with cloud-hosted services. It was back in early 2005, about a year before S3 was announced, and I was at a different company working on a technical due diligence project for a corporate…

The cloud helps organizations achieve unmatched resiliency at scale. This is a quick write-up I did on the AWS approach to resiliency: Reinventing Operational Resiliency. A talk I did at re:Invent focused on AWS infrastructure: Tuesday Night Live with James Hamilton. Graviton AWS Arm server announcement: M6g, C6g, and R6g EC2 instances powered by Graviton2.

I was recently in a super interesting discussion mostly focused on energy efficiency and, as part of the discussion, the claim was raised that Nobel Laureate Richard Smalley was right when he said that Energy was the number one challenge facing our planet. I’m a pretty big believer in energy efficiency and the importance of…

At Tuesday Night Live with James Hamilton at the 2016 AWS re:Invent conference, I introduced the first Amazon Web Services custom silicon. The ASIC I showed formed the foundational core of our second generation custom network interface controllers and, even back in 2016, there was at least one of these ASICs going into every new…
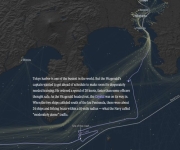
At 1:30:34AM on Jun 17, 2017 the USS Fitzgerald and the container ship ACX Crystal came together just south of Yokosuka Japan. The ACX Crystal is a 730’ modern containership built in 2008 and capable of carrying 2,858 TEU of containers at a 23-knot service speed. The Fitzgerald is a $1.8B US Navy Arleigh Burke-Class Destroyer…

Many years ago I worked on IBM DB2 and so I occasionally get the question, “how the heck could you folks possibly have four relational database management system code bases?” Some go on to argue that a single code base would have been much more efficient. That’s certainly true. And, had we moved to a…

Atlanta Hartsfield-Jackson International Airport suffered a massive power failure yesterday where the entire facility except for emergency lighting and safety equipment was down for nearly 11 hours. The popular press coverage on this power failure is extensive but here are two examples: WSJ: https://www.wsj.com/articles/power-outage-halts-flights-at-atlanta-international-airport-1513543883 (pay wall) CNN: http://edition.cnn.com/2017/12/17/us/atlanta-airport-power-outage/index.html For most years since 1998, Atlanta International…

This morning, I was thinking about Apple. When I got started in this industry in the early 80s, it was on an Apple II+ writing first in BASIC and later in UCSD Pascal. I thought Apple was simply amazing, so it was tough watching the more than decade of decline before Jobs rejoined. Our industry…

This morning I’m thinking through what I’m going to say at the AWS re:Invent Conference next week and I suppose I’m in a distractable mood. When an email came in asking “what advice would you give someone entering the information technology industry in 2017?” I gave it some thought. This was my short take: Play…

David Patterson has had a phenomenal impact on computer architecture and computer science over the last 40 years. He’s perhaps most notable for the industry impact of the projects he’s led over these years. I first got to know his work back when the Berkeley Reduced Instruction Set Computer project started publishing. The RISC project…

March 14, 2006 was the beginning of a new era in computing. That was the day that Amazon Web Services released the Simple Storage Service (S3). Technically, Simple Queuing Services was released earlier but it was the release of S3 that really lit the fire under cloud computing. I remember that day well. At the…

I’m an avid reader of engineering disasters since one of my primary roles in my day job is to avoid them. And, away from work, we are taking a small boat around the world with only two people on board and that too needs to be done with care where an engineering or operational mistake…